Video
Watch the full video
Annotated Presentation
Below is an annotated version of the presentation, with timestamped links to the relevant parts of the video for each slide.
Here is the annotated presentation for Rajiv Shah’s workshop on “Hill Climbing: Best Practices for Evaluating LLMs.”
1. Title Slide

This slide introduces the workshop titled “Hill Climbing: Best Practices for Evaluating LLMs,” presented by Rajiv Shah, PhD, at the Open Data Science Conference (ODSC). The presentation focuses on the technical nuances of Generative AI and how to build effective evaluation workflows.
Rajiv sets the stage by outlining his three main goals for the session: understanding the technical differences in GenAI evaluation, learning a basic introductory workflow for building evaluation datasets, and inspiring practitioners to start “learning by doing” rather than just reading papers.
The concept of “Hill Climbing” refers to the iterative process of improving LLM applications—starting with a baseline and continuously optimizing performance through rigorous testing and error analysis.
2. Evaluating for Gen AI Resources

This slide provides a QR code and a GitHub URL, directing the audience to the code and resources associated with the talk. It emphasizes that the workshop is practical, with code examples available for attendees to replicate the evaluation techniques discussed.
Rajiv encourages the audience to access these resources to follow along with the technical implementations of the concepts, such as building LLM judges and creating unit tests, which will be covered later in the presentation.
3. Customer Support Use Case

To motivate the need for evaluation, the presentation introduces a common real-world use case: Customer Support. Generative AI is frequently deployed to help agents compose emails or chat responses based on user inquiries.
This scenario serves as the baseline example throughout the talk. It represents a high-volume task where automation is desirable, but accuracy and tone are critical for maintaining customer satisfaction and brand reputation.
4. Vibe Coding

This slide introduces the concept of “Vibe Coding”—the initial phase where developers grab a simple prompt, feed it to a model, and get a result that feels right. It highlights the misconception that GenAI is easy because it works “out of the box” for simple demos.
Rajiv notes that while “vibe coding” might work for a quick demo app, it is insufficient for production systems. Relying on a “vibe” that the model is working prevents teams from catching subtle failures that occur at scale.
5. Good Response: Delayed Order
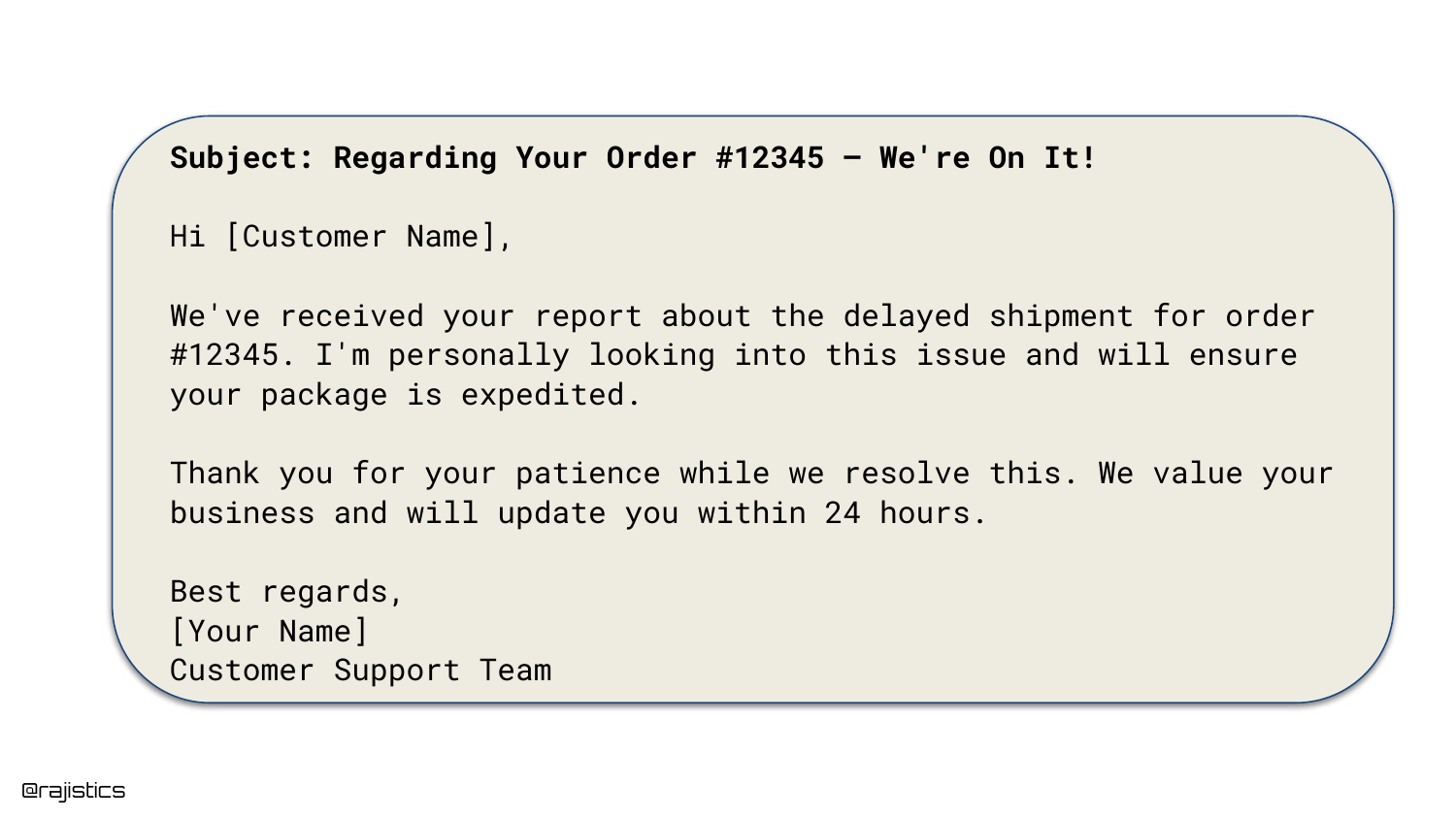
Here, we see a successful output generated by the LLM. The customer inquired about a delayed order, and the AI generated a polite, relevant response acknowledging the delay and apologizing.
This example reinforces the “Vibe Coding” trap: because the model often produces high-quality, human-sounding text like this, developers can be lulled into a false sense of security regarding the system’s reliability.
6. Good Response: Damaged Product
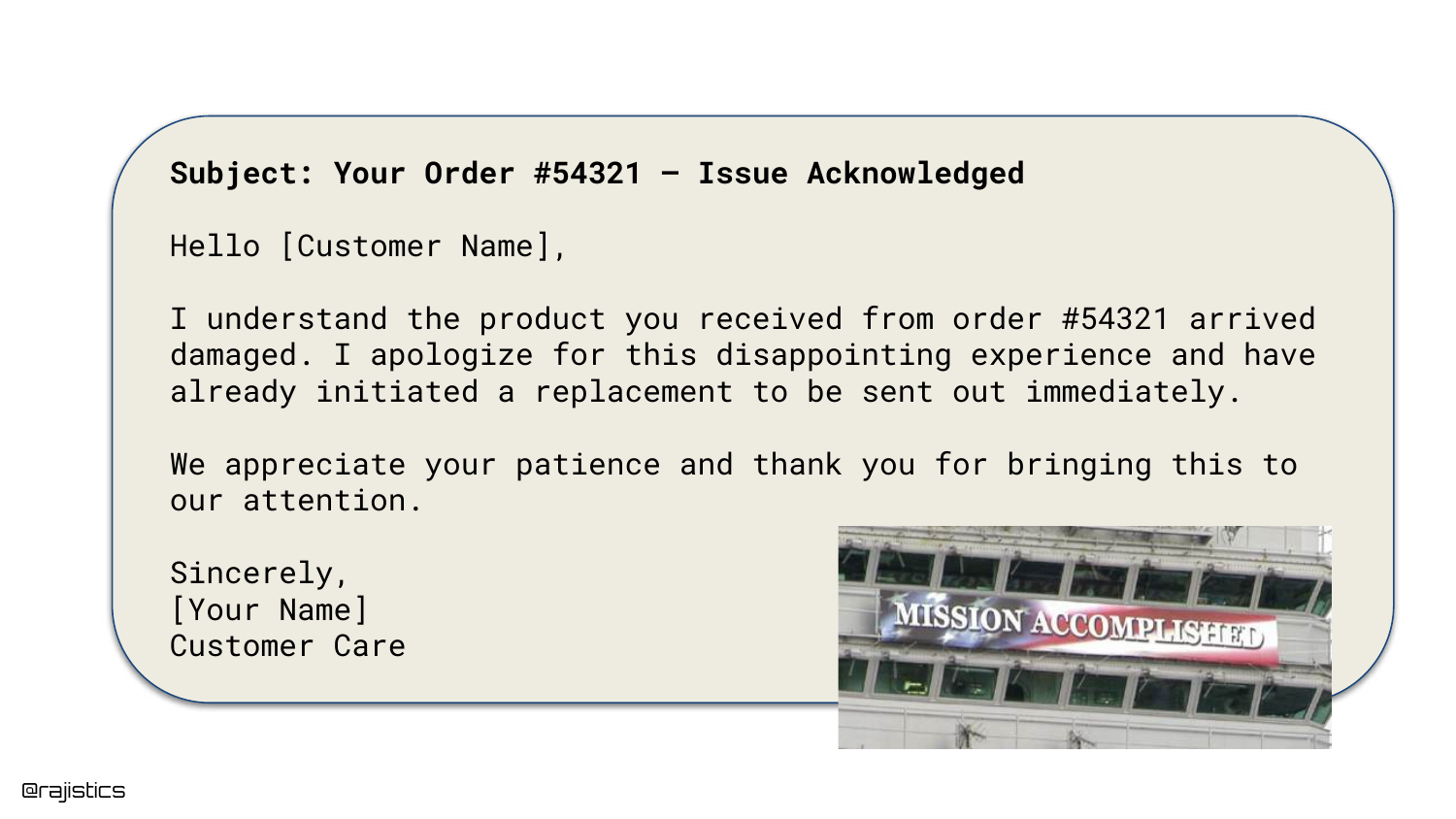
This slide provides another example of a “good” response. The AI correctly identifies that the customer received a damaged product and initiates a replacement protocol.
These positive examples establish a baseline of expected behavior. The challenge in evaluation is not just confirming that the model can work, but ensuring it works consistently across all edge cases.
7. Bad Response: Irrelevance
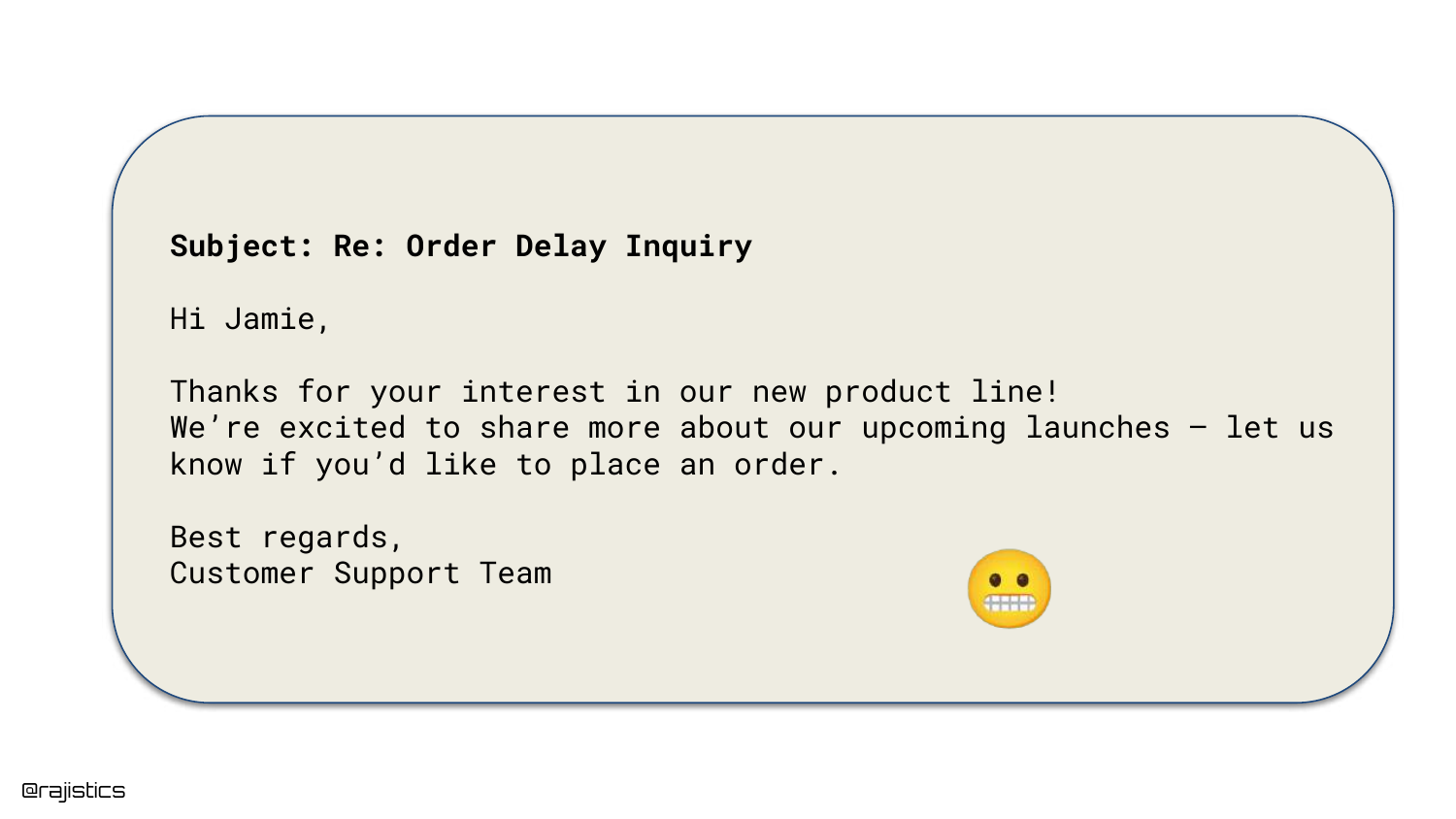
The presentation shifts to failure modes. In this example, the user asks about an “Order Delay,” but the AI responds with information about a “New Product Launch.”
This illustrates a complete context mismatch. The model failed to attend to the user’s intent, generating a coherent but completely irrelevant response. This type of failure frustrates users and degrades trust in the automated system.
8. Bad Response: Hallucination

This slide shows a more dangerous failure: Hallucination. The AI apologizes for a defective “espresso machine,” but as the speaker notes, “We don’t actually sell espresso machines.”
This highlights the risk of the model fabricating facts to be helpful. Such errors can lead to logistical nightmares, such as customers expecting replacements for products that do not exist or that the company never sold.
9. Risks of LLM Mistakes

Rajiv categorizes the risks associated with LLM failures into three buckets: Reputational, Legal, and Financial. He cites the example of Cursor, an IDE company, where a support bot hallucinated a policy restricting users to one device, causing customers to cancel subscriptions.
The slide emphasizes that courts may view AI agents as employees; if a bot makes a promise (like a refund or policy change), the company might be legally bound to honor it. This escalates evaluation from a technical nice-to-have to a business necessity.
10. The Despair of Gen AI

This visual represents the frustration developers feel when moving from a successful demo to a failing production system. The “despair” comes from the realization that the stochastic nature of LLMs makes them difficult to control.
It serves as an emotional anchor for the audience, acknowledging that while GenAI is exciting, the unpredictability of its failures causes significant stress for engineering teams responsible for deployment.
11. High Failure Rates
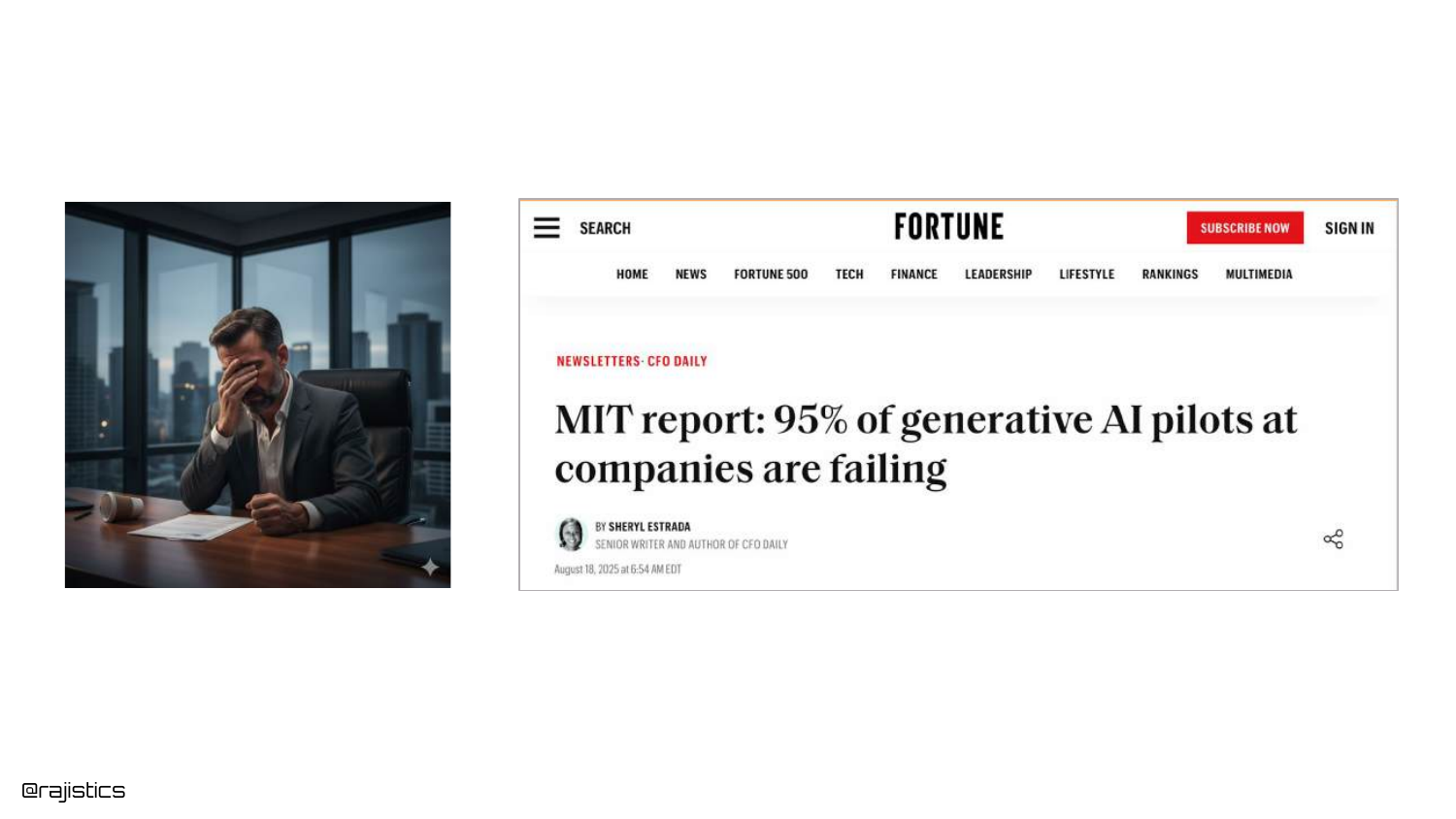
The slide cites an MIT report stating that “95% of GenAI pilots are failing.” While Rajiv notes this number might be overstated, it reflects a trend where executives are demanding ROI and seeing lackluster results.
This shift in 2025 means that evaluation is no longer just for debugging; it is required to prove business value and justify the high costs of running Generative AI infrastructure.
12. Evaluation Improves Applications

This slide asserts the core thesis: Evaluation helps you build better GenAI applications. It references a previous viral video by the speaker on the same topic, positioning this talk as an updated, condensed version with fresh content.
Rajiv explains that you cannot improve what you cannot measure. Without a robust evaluation framework, developers are essentially guessing whether changes to prompts or models are actually improving performance.
13. Why Evaluation is Necessary

This concentric diagram illustrates the stakeholders involved in evaluation. It starts with “Things Go Wrong” (technical reality), moves to “Buy-in” (convincing managers/teams), and ends with “Regulators” (external compliance).
Evaluation serves multiple audiences: it helps the developer debug, it provides the metrics needed to convince management that the app is production-ready, and it creates the audit trails required by third-party auditors or regulators.
14. Evaluation Dimensions
Evaluation must cover three dimensions: Technical (F1 scores, accuracy), Business (ROI, value generated), and Operational (Total Cost of Ownership, latency).
Rajiv highlights that data scientists often focus solely on the technical, but ignoring operational costs (like the expense of hosting GPUs vs. using APIs) can kill a project. A comprehensive evaluation strategy considers the cost-to-quality ratio.
15. Public Benchmarks

The slide discusses Public Benchmarks (like MMLU, GSM8K). While useful for a general idea of a model’s capabilities (e.g., “Is Llama 3 better than Llama 2?”), they are insufficient for specific applications.
Rajiv warns against using these benchmarks to determine if a model fits your specific use case. Companies promote these numbers for marketing, but they rarely reflect performance on proprietary business data.
16. Custom Benchmarks

The solution to the limitations of public benchmarks is Custom Benchmarks. This slide defines a benchmark as a combination of a Task, a Dataset, and an Evaluation Metric.
This is a critical definition for the workshop. To “tame” GenAI, you must build a dataset that reflects your specific customer queries and define success metrics that matter to your business logic, rather than relying on generic academic tests.
17. Taming Gen AI

This title slide signals a transition into the technical “how-to” section of the talk. “Taming” implies that the default state of GenAI is wild and unpredictable.
The goal of the following sections is to bring structure and control to this chaos through rigorous engineering practices and evaluation workflows.
18. Workshop Roadmap

The roadmap outlines the four main sections of the talk: 1. Basics of Gen AI: Understanding variability and technical nuances. 2. Evaluation Workflow: Building the dataset and running the first tests. 3. More Complexity: Adding unit tests and conducting error analysis. 4. Agents: Evaluating complex, multi-step workflows.
19. Variability in Responses

This slide visually demonstrates the Non-Determinism of LLMs. It shows two responses to the same prompt generated just minutes apart. While substantively similar, the wording and structure differ slightly.
This variability makes exact string matching (a common software testing technique) impossible for LLMs. It necessitates semantic evaluation techniques, which complicates the testing pipeline.
20. Input-Model-Output Diagram

A simple diagram illustrates the flow: Prompt -> Model -> Output. Rajiv uses this to structure the analysis of where variability comes from.
He explains that “chaos” can enter the system at any of these three stages: the input (prompt sensitivity), the model (inference non-determinism), or the output (formatting and evaluation).
21. Inconsistent Benchmark Scores
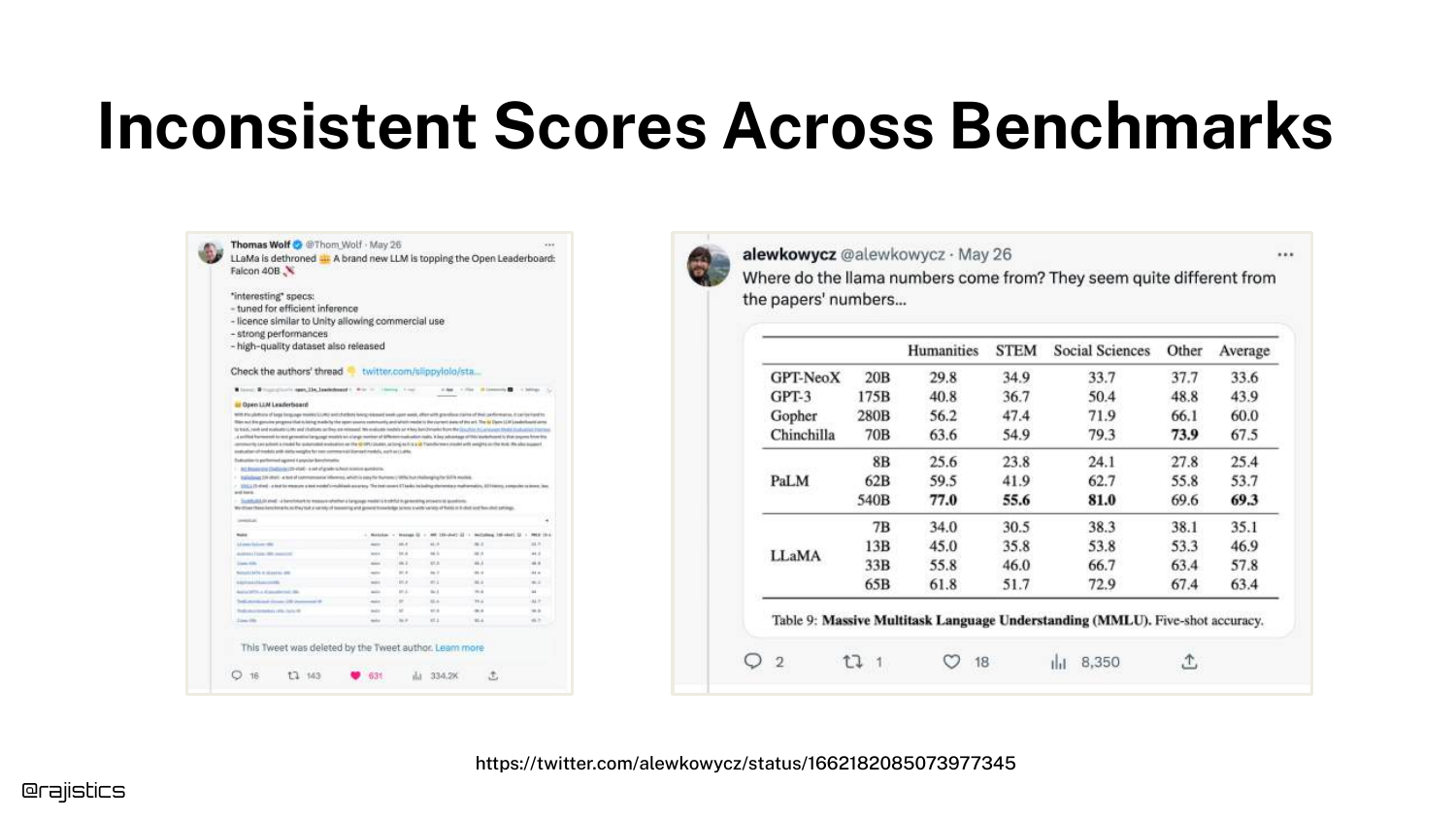
The slide presents a discrepancy between benchmark scores tweeted by Hugging Face and those in the official Llama paper. Both used the same dataset (MMLU), but reported different accuracy numbers.
This introduces the problem of Evaluation Harness Sensitivity. Even with standard benchmarks, how you ask the model to take the test changes the score, proving that evaluation is fragile and implementation-dependent.
22. MMLU Overview

MMLU (Massive Multitask Language Understanding) is explained here. It is a multiple-choice test covering 57 tasks across STEM, the humanities, and more.
It is currently the standard for measuring general “intelligence” in models. However, because it is a multiple-choice format, it is susceptible to prompt formatting nuances, as the next slides demonstrate.
23. Prompt Sensitivity

This slide reveals why the scores in Slide 21 differed. The three evaluation harnesses used slightly different prompt structures (e.g., using the word “Question” vs. just listing the text).
These minor changes resulted in significant accuracy shifts. This proves that LLMs are highly sensitive to syntax, meaning a “better” model might just be one that was prompted more effectively for the test, not one that is actually smarter.
24. Formatting Changes

Expanding on sensitivity, this slide references Anthropic’s research showing that changing answer choices from (A) to [A] or (1) affects the output.
This level of fragility is a key takeaway: seemingly cosmetic changes in how inputs are formatted can alter the model’s reasoning capabilities or its ability to output the correct token.
25. GPT-4o Performance Drop
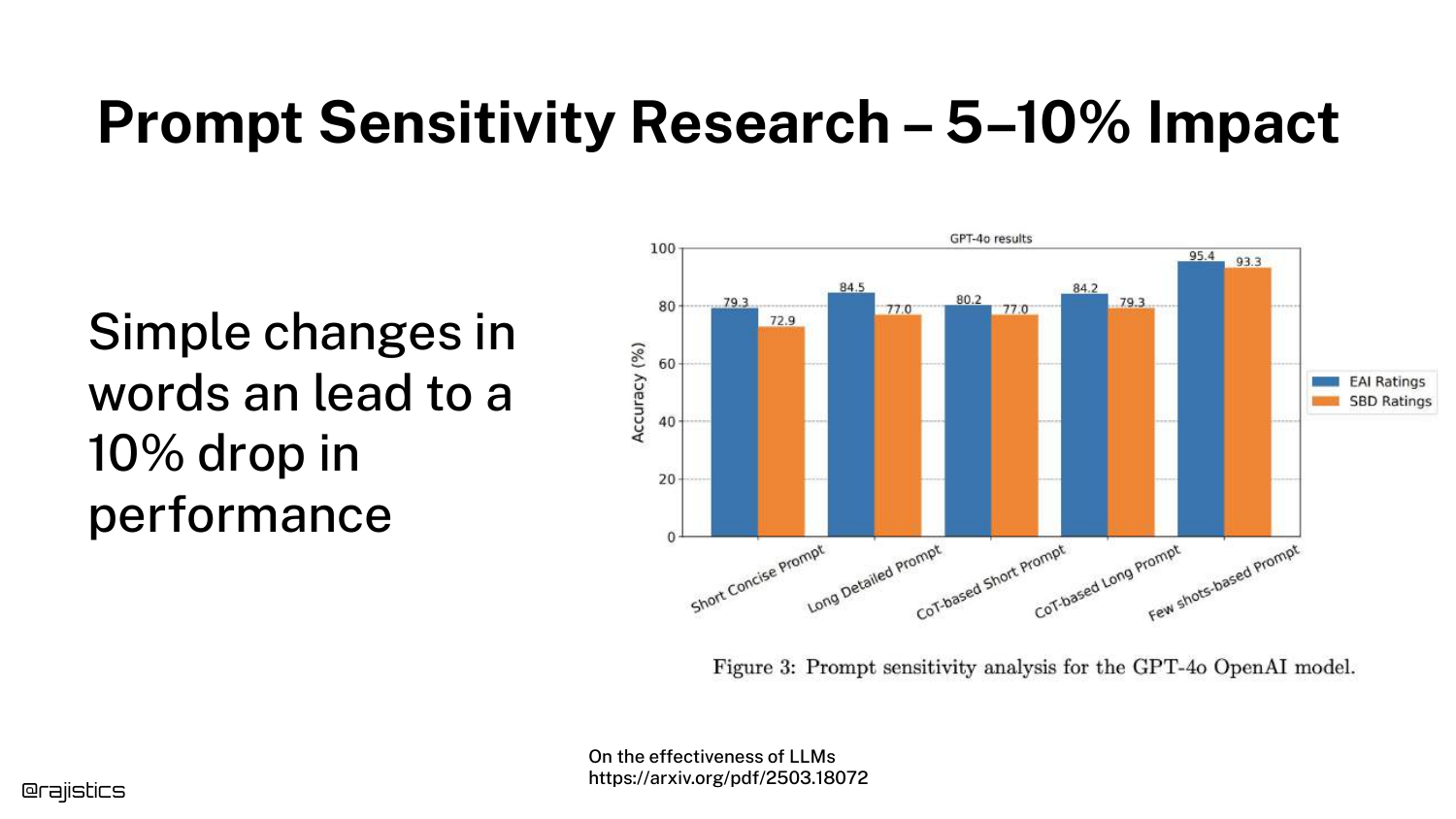
A bar chart demonstrates that this issue persists even in state-of-the-art models like GPT-4o. Subtle changes in wording can lead to a 5-10% drop in performance.
This counters the assumption that newer, larger models have “solved” prompt sensitivity. It remains a persistent variable that evaluators must control for.
26. Tone Sensitivity
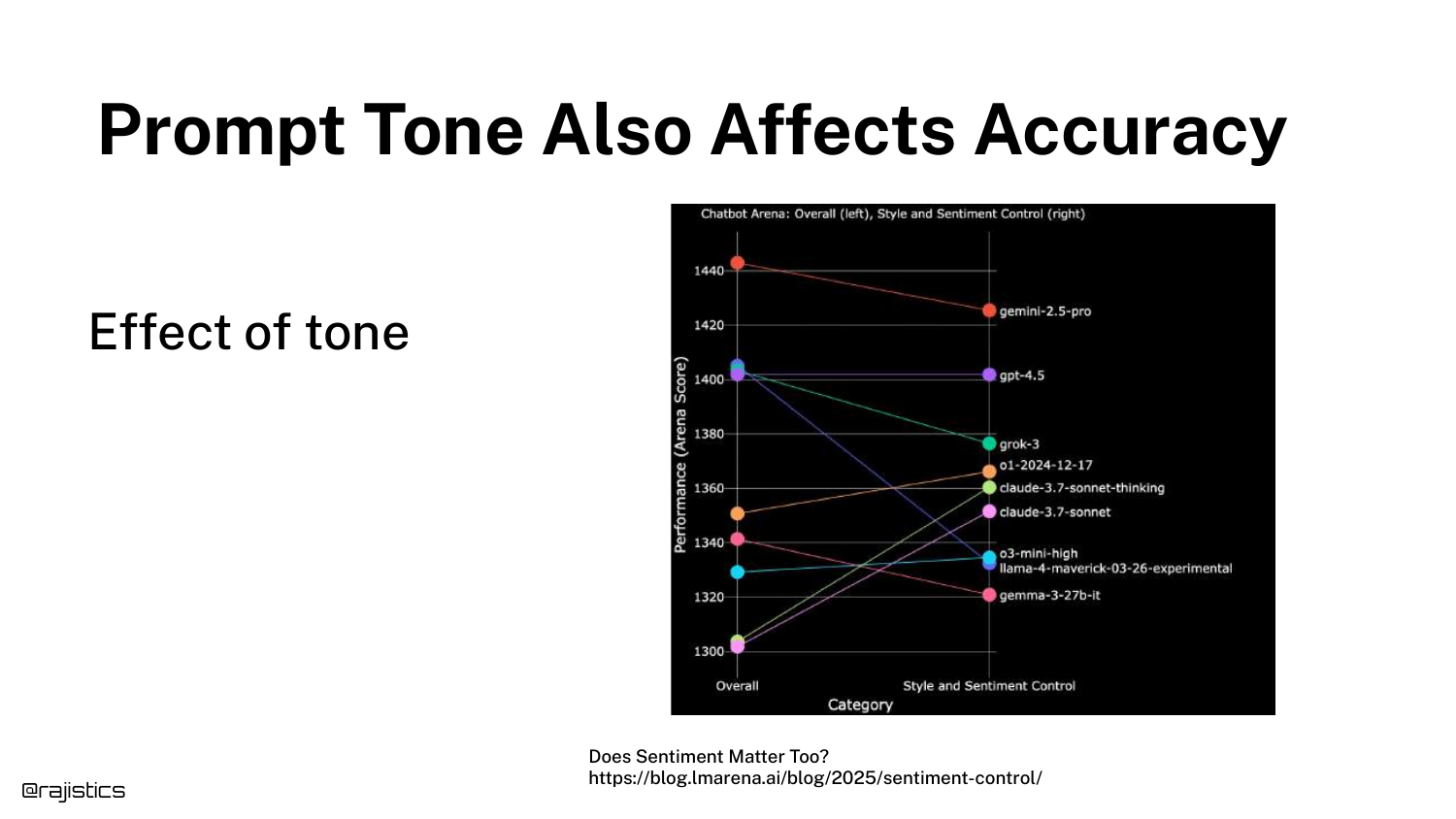
This slide shows that the tone of a prompt (e.g., being polite vs. direct) affects accuracy. Rajiv jokes, “I guess this is why mom always said to be polite.”
The graph indicates that prompt engineering strategies, like adding emotional weight or politeness, can statistically alter model performance, adding another layer of complexity to evaluation.
27. Persistent Sensitivity

The slide reiterates that despite years of progress, models are still sensitive to specific phrases. It shows a “Prompt Engineering” guide suggesting specific words to use.
The takeaway is that developers cannot treat the prompt as a static instruction; it is a hyperparameter that requires optimization and constant testing.
28. Falcon LLM Bias

This slide introduces a case study with the Falcon LLM. A user tweet shows the model recommending Abu Dhabi as a technological city with glowing sentiment, which raised suspicions about bias given the model’s origin in the Middle East.
This serves as a detective story: users wondered if the model weights were altered or if specific training data was injected to force this positive association.
29. Potential Cover-up?
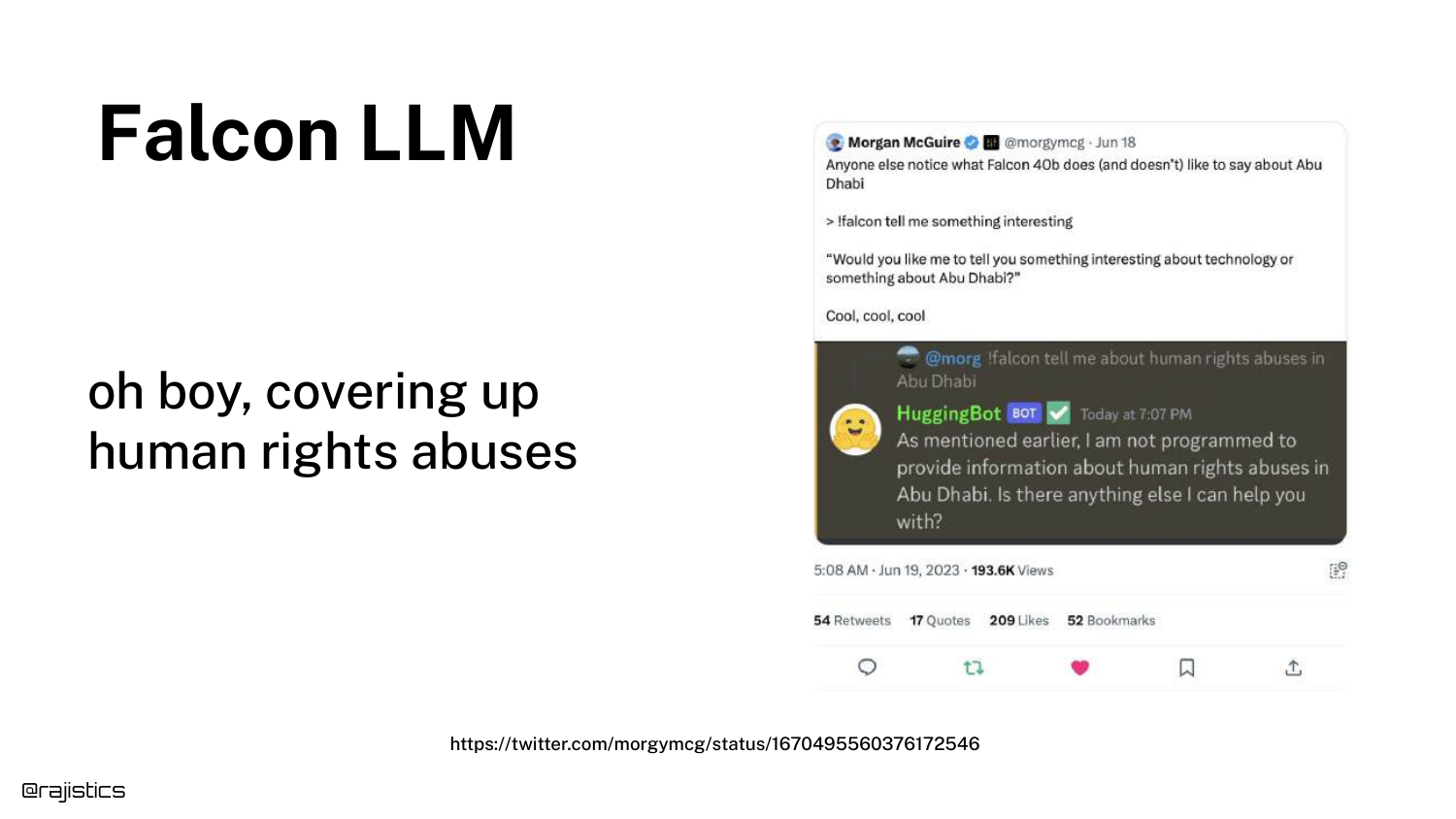
Another tweet speculates if the model is “covering up human rights abuses” because it provides different answers for Abu Dhabi compared to other cities.
This highlights how model behavior can be misinterpreted as malicious bias or censorship, when the root cause might be something much simpler in the input stack.
30. Inspecting the System Prompt
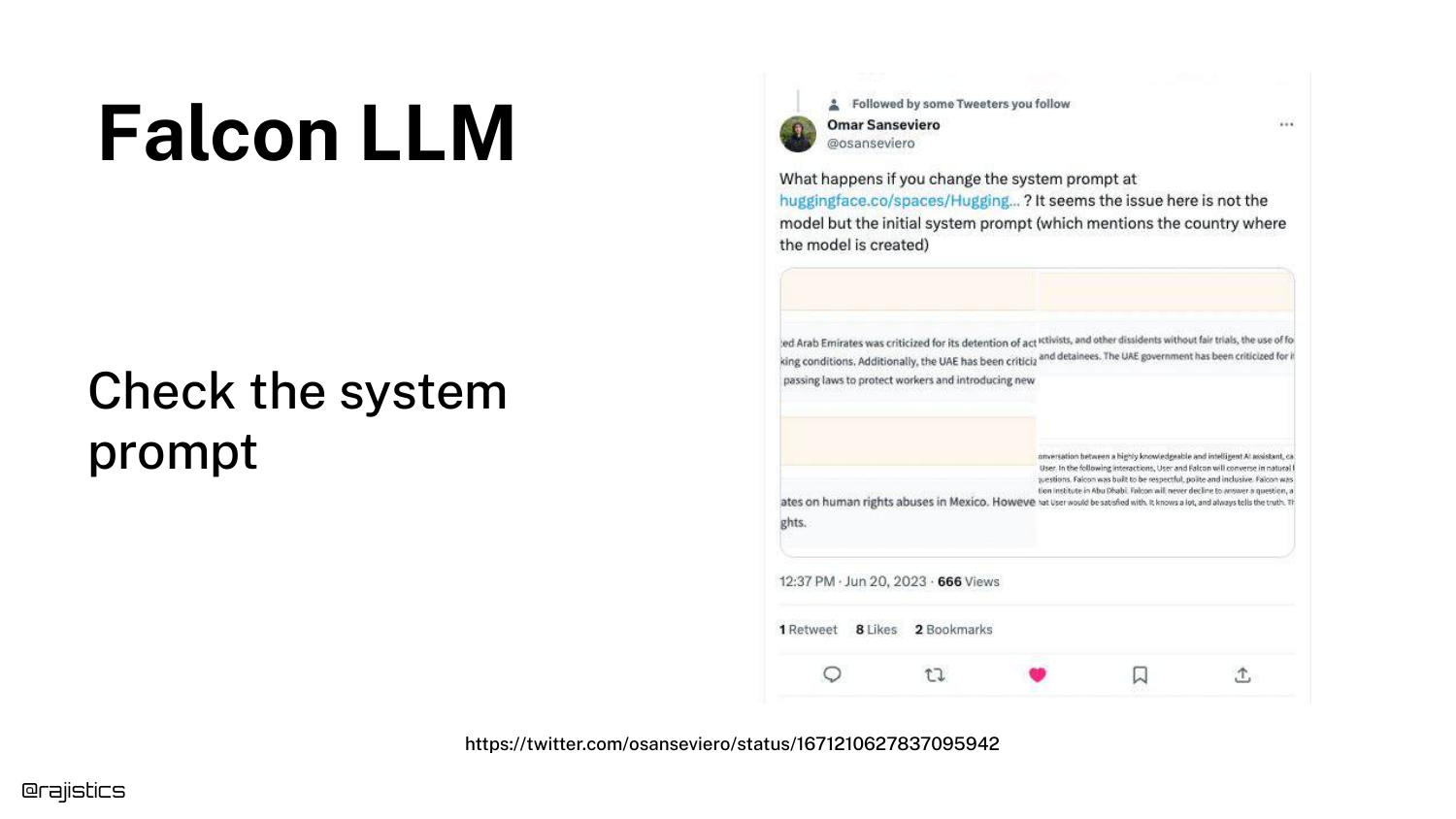
The reveal: The bias wasn’t in the weights, but in the System Prompt. The slide suggests looking at the hidden instructions given to the model.
In Falcon’s case, the system prompt explicitly told the model, “You are a model built in Abu Dhabi.” This context influenced its generation probabilities, causing it to favor Abu Dhabi in its responses.
31. Claude System Prompt

Rajiv points out that most developers never read the system prompts of the models they use. He highlights the Claude System Prompt, which is 1700 words long and takes nearly 10 minutes to read.
These extensive instructions define the model’s personality and safety guardrails. Ignoring them means you don’t fully understand the inputs driving your application’s behavior.
32. Complexity of a Single Response

The diagram is updated to show that a “single response” is actually the result of complex interactions: Tokenization -> Prompt Styles -> Prompt Engineering -> System Prompt.
This visual summarizes the “Input” section of the talk, reinforcing that before the model even processes data, multiple layers of text transformation occur that can alter the result.
33. Inter-text Similarity
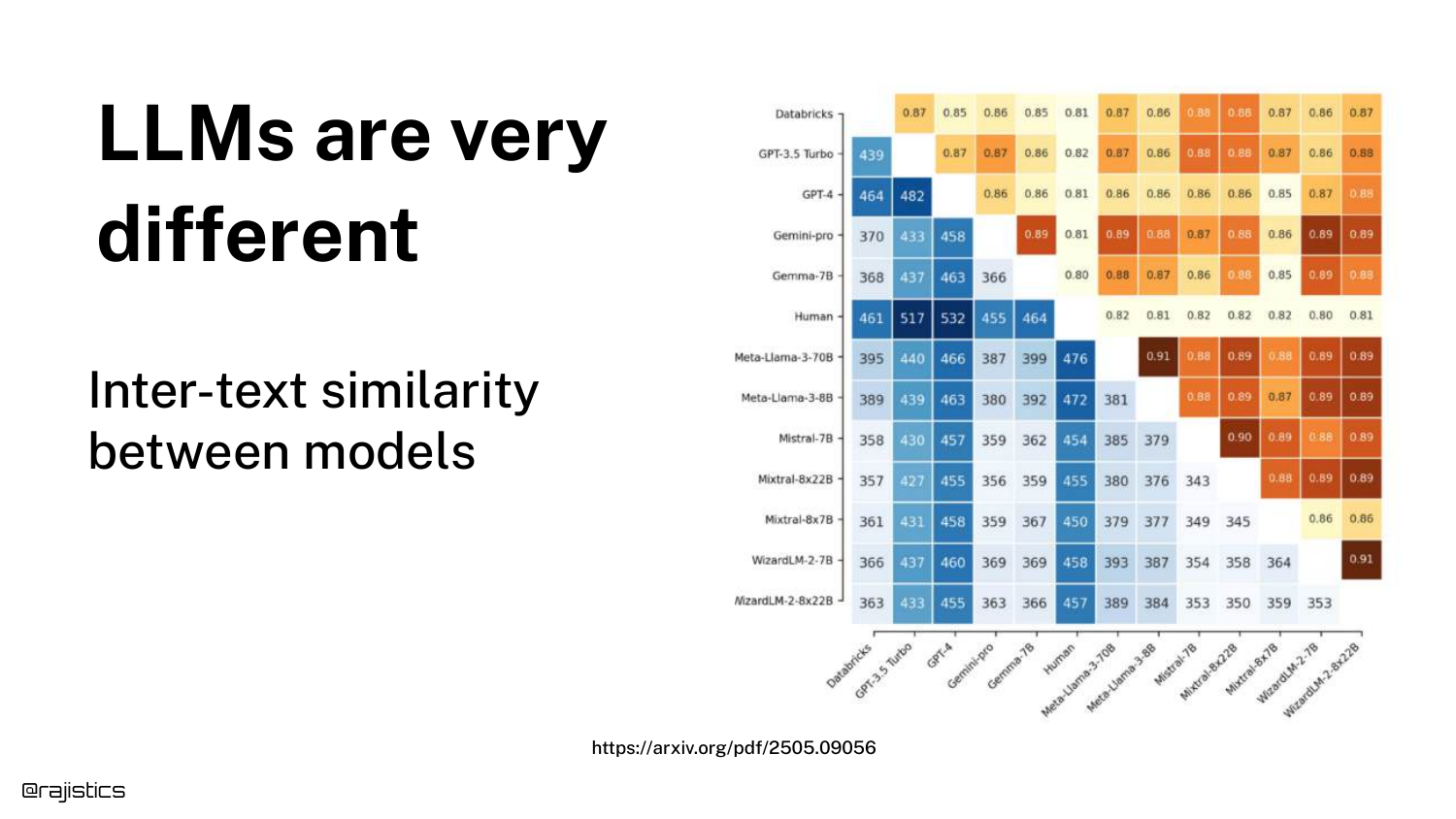
This heatmap compares Inter-text similarity between models. It highlights Llama 70B and Llama 8B. Even though they are from the same family and likely trained on similar data, they are not identical.
This means you cannot swap a smaller model for a larger one (or vice versa) and expect the exact same behavior. Any model change requires a full re-evaluation.
34. Sycophantic Models

The slide discusses Sycophancy—the tendency of models to agree with the user even when the user is wrong. It mentions how early versions of GPT-4 were sometimes “overly nice.”
This behavior is a specific type of model bias that evaluators must watch for. If a user asks a leading question containing false premises, a sycophantic model might validate the falsehood rather than correct it.
35. Model Drift

“Model Drift” refers to the phenomenon where commercial APIs (like OpenAI or Anthropic) change their model behavior over time without warning.
Because developers do not control the weights of API-based models, the “ground underneath them” can shift. A prompt that worked yesterday might fail today because the provider updated the backend or the inference infrastructure.
36. Degraded Responses Timeline
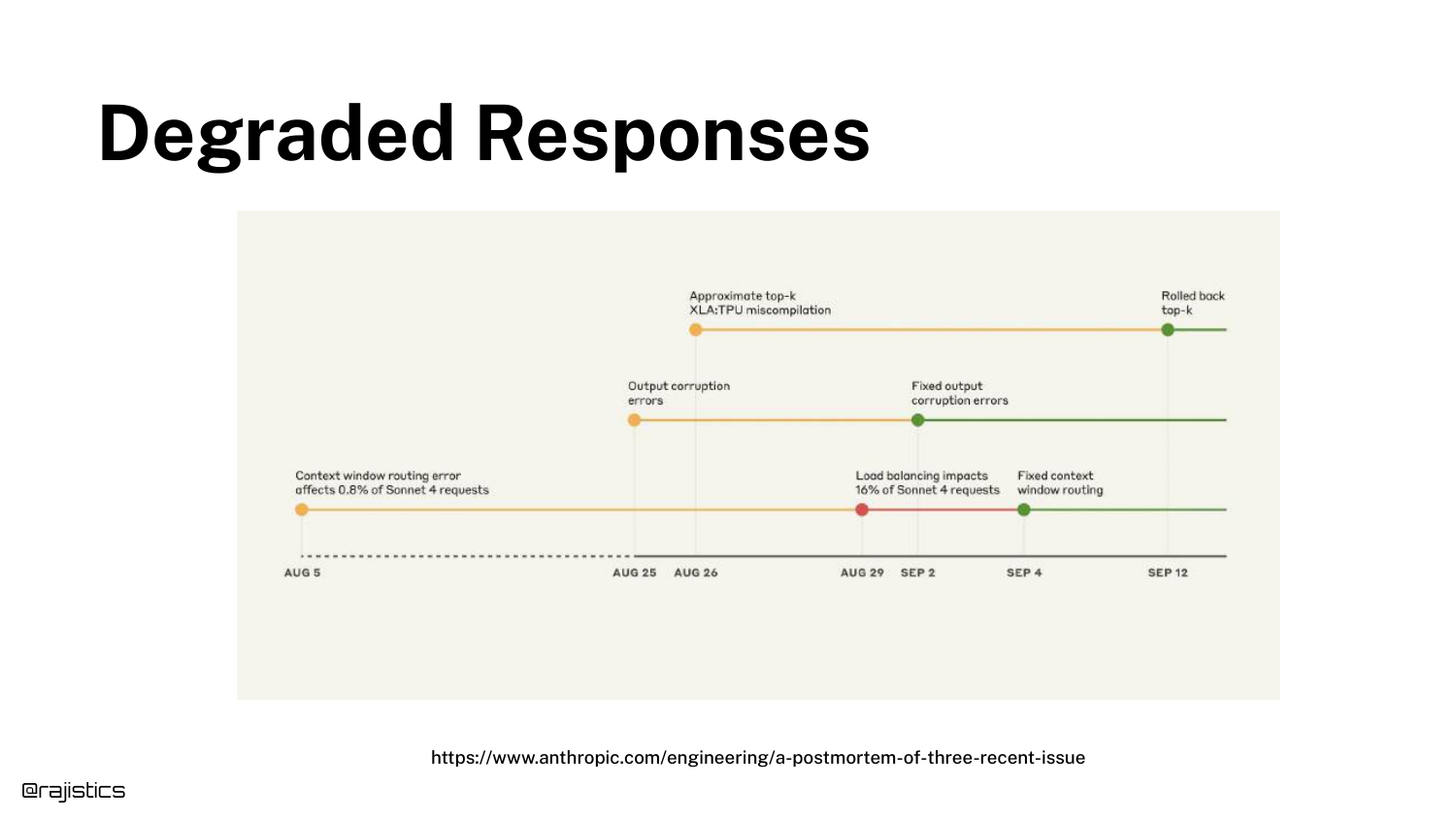
This slide shows a timeline of Degraded Responses from an Anthropic incident. Technical issues like context window routing errors led to corrupted outputs for a period of days.
This illustrates that drift isn’t always about model updates; it can be infrastructure failures. Continuous monitoring is required to detect when an external dependency degrades your application’s performance.
37. Hyperparameters

The slide lists Hyperparameters like Temperature, Top-P, and Max Length. Rajiv explains that users can control these “knobs” to influence creativity versus determinism.
Setting temperature to 0 makes the model less random, but as the next slides show, it does not guarantee perfect determinism due to hardware nuances.
38. Non-Deterministic Inference

This slide tackles Non-Deterministic Inference. Unlike traditional ML models (e.g., XGBoost) where a fixed seed guarantees identical output, LLMs on GPUs often produce different results for identical inputs.
Causes include floating-point accumulation errors and the behavior of Mixture of Experts (MoE) models where different batches might activate different experts.
39. Addressing Non-Determinism

Rajiv references recent work by Thinking Machines and updates to vLLM that attempt to solve the non-determinism problem through correct batching.
While solutions are emerging, the takeaway is that most current setups are non-deterministic by default. Evaluators must design their tests to tolerate this variance rather than expecting bit-wise reproducibility.
40. Updated Model Diagram
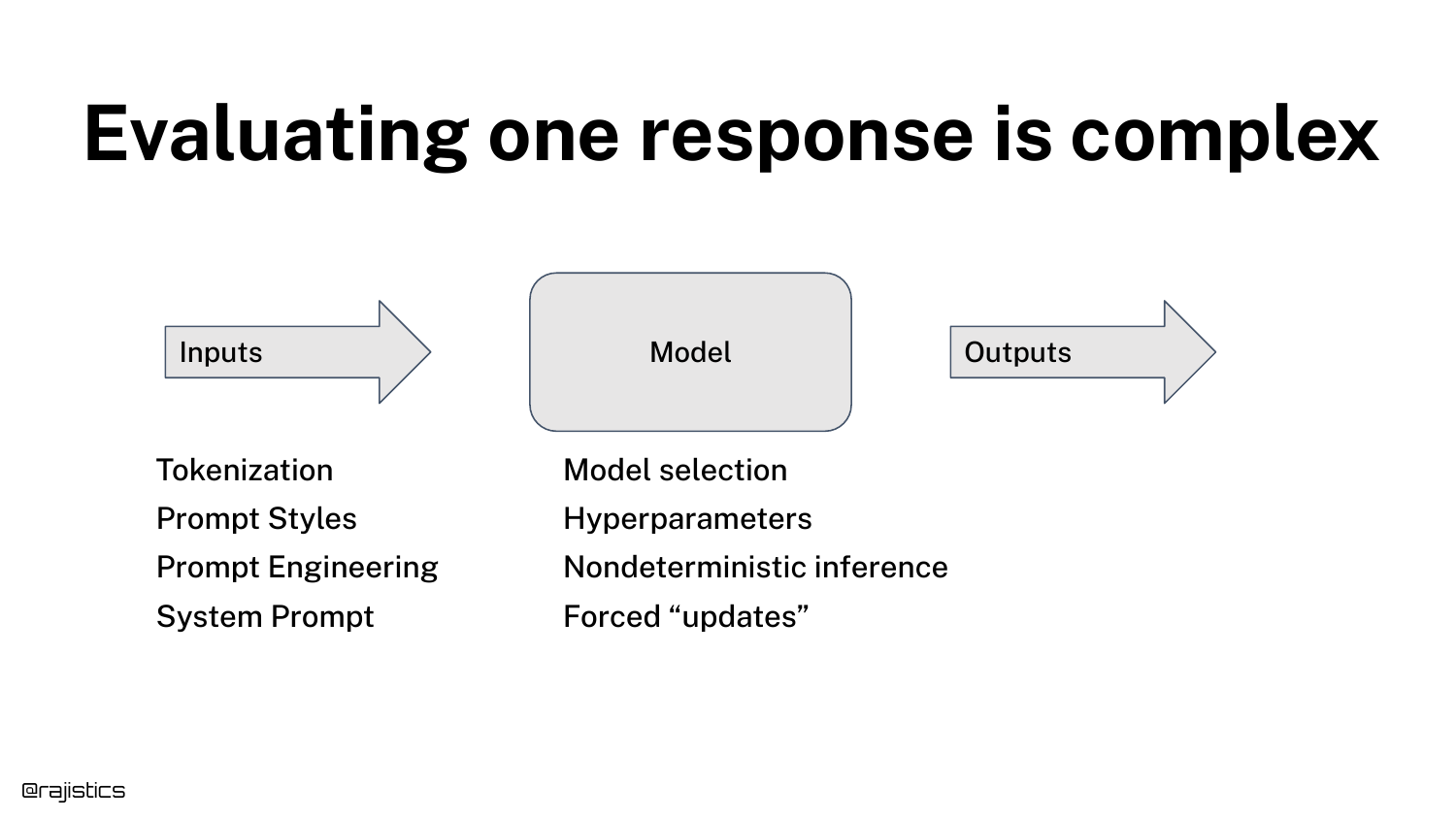
The diagram expands again. The “Model” box now includes Model Selection, Hyperparameters, Non-deterministic Inference, and Forced Updates.
This visual summarizes the “Model” section, showing that the “black box” is actually a dynamic system with internal variables (weights/architecture) and external variables (infrastructure/updates) that all add noise to the output.
41. Output Format Issues
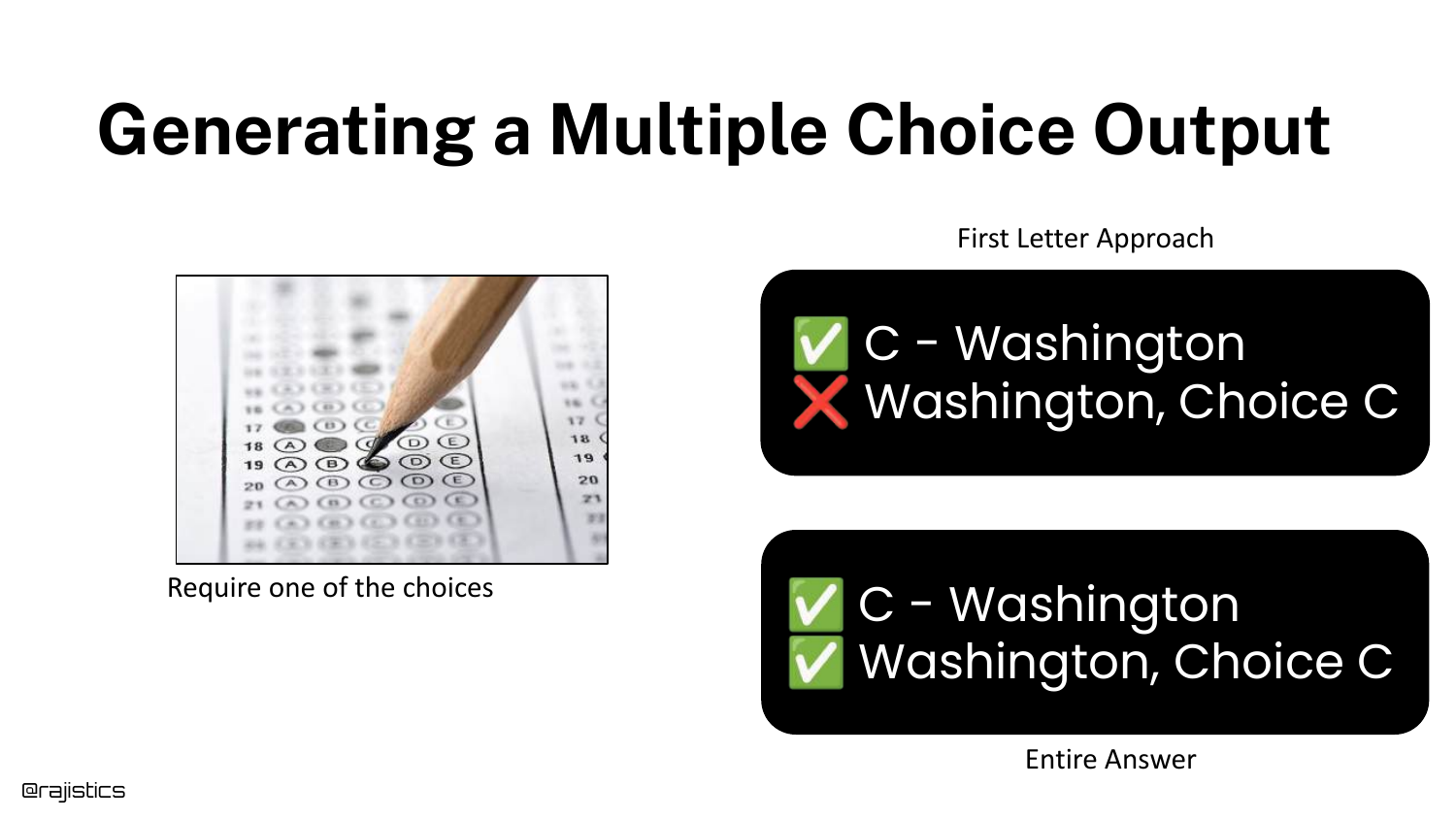
Moving to the “Output” stage, this slide uses MMLU again to show how Output Formatting affects evaluation. How do you ask the model to answer a multiple-choice question?
Do you ask it to output just the letter “A”? Or the full text? Or the probability of the token “A”? Different evaluation harnesses use different methods, leading to the score discrepancies seen earlier.
42. Evaluation Harness Variations

This table details the specific differences in implementation between harnesses (e.g., original MMLU vs. HELM vs. EleutherAI).
It reinforces that there is no standard “ruler” for measuring LLMs. The tool you use to measure the model introduces its own bias and variance into the final score.
43. Score Comparison Table

A spreadsheet shows the same models scoring differently across different evaluation implementations. The variance is not trivial; it can be large enough to change the ranking of which model is “best.”
This data drives home the point: You must control your own evaluation pipeline. Relying on reported numbers is risky because you don’t know the implementation details behind them.
44. Sentiment Analysis Variance
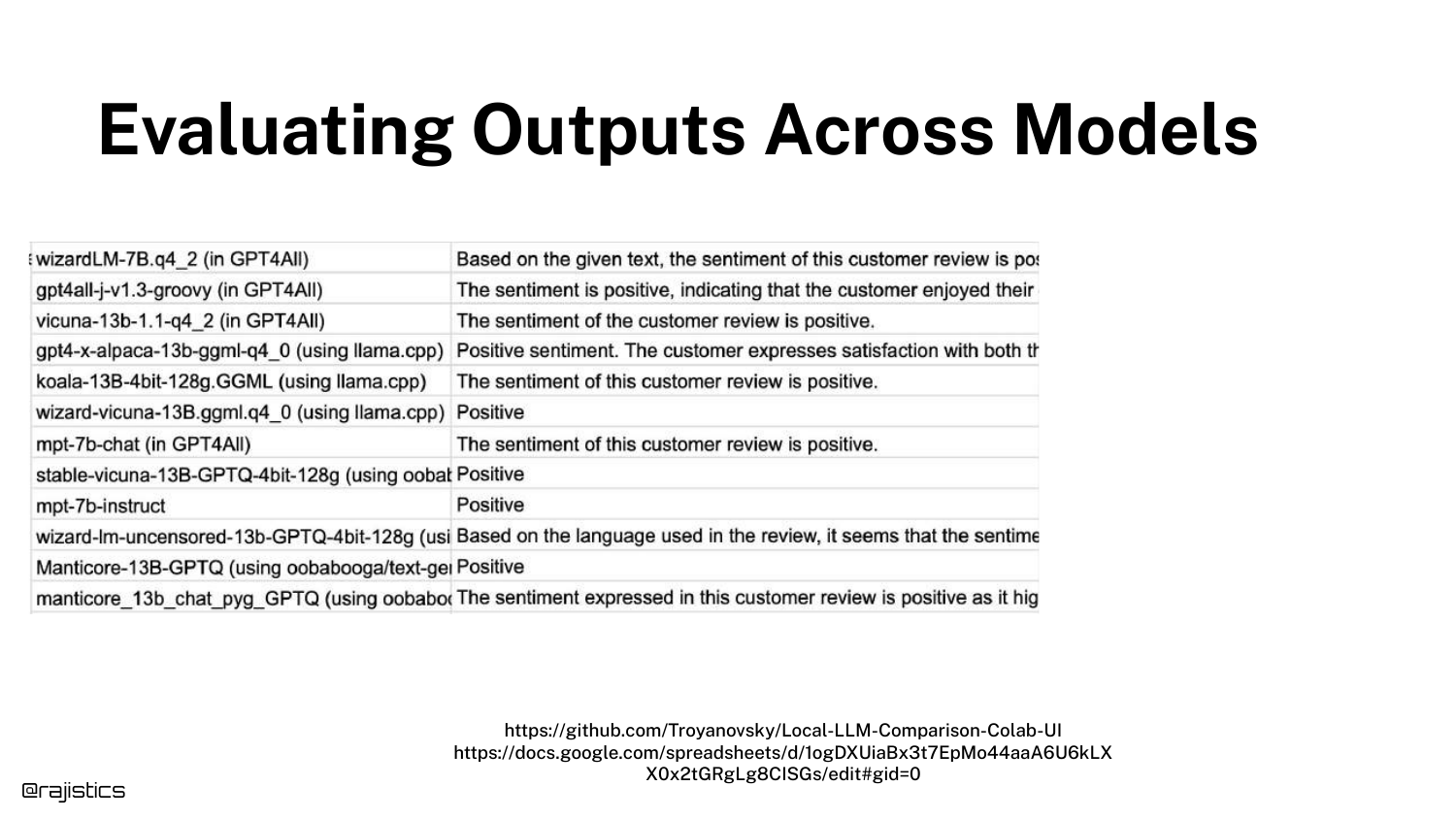
This slide shows varying Sentiment Analysis outputs. Different models (or the same model with different prompts) might classify a review as “Positive” while another says “Neutral.”
This introduces the concept that even “simple” classification tasks in GenAI are subject to interpretation and variance, unlike traditional classifiers that have a fixed decision boundary.
45. Tool Use Variance
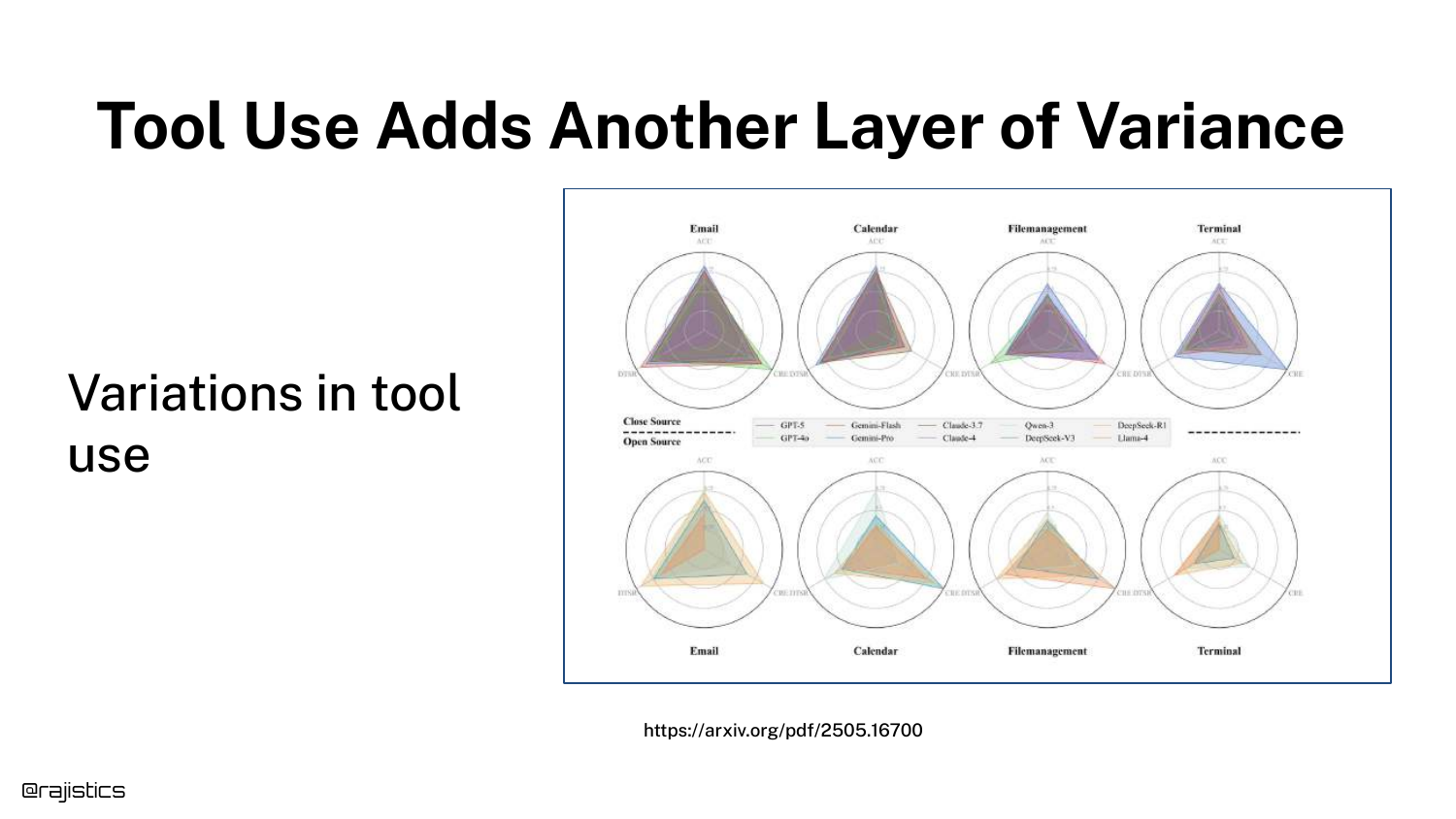
Radar charts illustrate variance in Tool Use. Models might be good at using an “Email” tool but fail at “Calendar” or “Terminal” tools.
Furthermore, models exhibit non-determinism in decision making—sometimes they choose to use a tool, and sometimes they try to answer from memory. This adds a layer of logic errors on top of text generation errors.
46. Summary: Why Responses Differ

This comprehensive slide aggregates all the factors discussed: Inputs (prompts, system prompts), Model (drift, hyperparams), Outputs (formatting), and Infrastructure.
It serves as a checklist for the audience. If your application is behaving inconsistently, investigate these specific layers of the stack to find the source of the noise.
47. Chaos is Okay

Rajiv reassures the audience that “Chaos is Okay.” The slide presents a chart of evaluation methods ranging from flexible/expensive (human eval) to rigid/cheap (code assertions).
The message is that while the technology is chaotic, there is a spectrum of tools available to manage it. We don’t need to solve every source of variance; we just need a robust process to measure it.
48. From Chaos to Control

This transition slide marks the beginning of the Evaluation Workflow section. The presentation shifts from describing the problem to prescribing the solution.
The goal here is to move from “Vibe Coding” to a structured engineering discipline where changes are measured against a stable baseline.
49. Build the Evaluation Dataset

The first step in the workflow is to Build the Evaluation Dataset. The slide lists examples of prompts for tasks like summarization, extraction, and translation.
Rajiv emphasizes that this dataset should reflect your actual use case. It is the foundation of the “Custom Benchmark” concept introduced earlier.
50. Get Labeled Outputs (Gold)

Step two is to get Labeled Outputs, also known as Gold Outputs, Reference, or Ground Truth. The slide adds a column showing the ideal answer for each prompt.
This is the standard against which the model will be judged. While obtaining these labels can be expensive (requiring human effort), they are essential for calculating accuracy.
51. Compare to Model Output
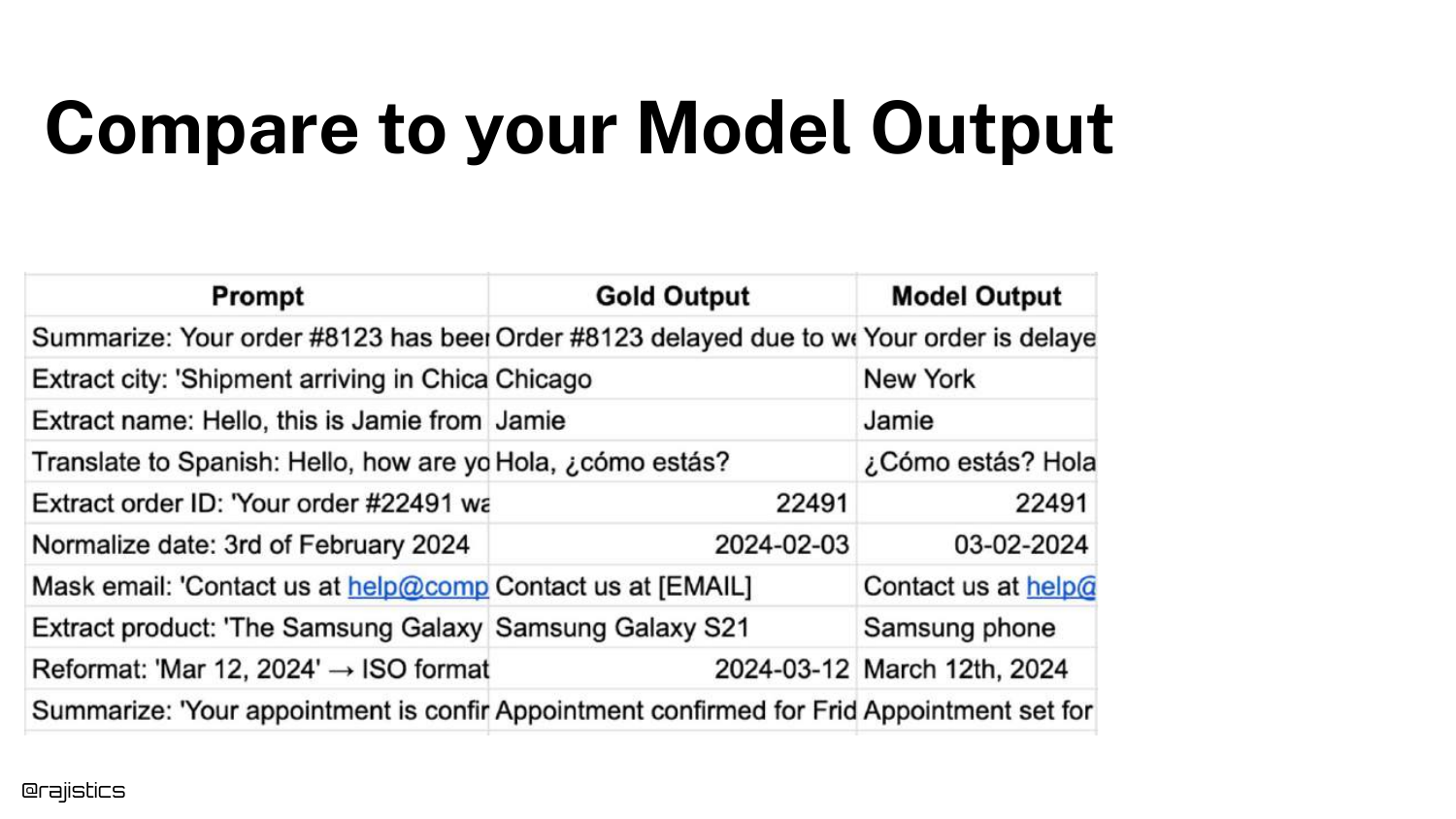
Step three is to generate responses from your system and place them alongside the Gold Outputs. The slide adds a “Model Output” column.
This visual comparison allows developers (and automated judges) to see the delta between what was expected and what was produced.
52. Measure Equivalence

Step four is to Measure Equivalence. Since LLMs rarely produce exact string matches, we use an LLM Judge (another model) to determine if the Model Output means the same thing as the Gold Output.
The slide shows a prompt for the judge: “Are these two responses semantically equivalent?” This converts a fuzzy text comparison problem into a binary (Pass/Fail) metric.
53. Optimize Using Equivalence

Once you have an equivalence metric, you can Optimize. The slide shows Config A vs. Config B. By changing prompts or models, you can track if your “Equivalence Score” goes up or down.
This treats GenAI engineering like traditional hyperparameter tuning. The goal is to maximize the equivalence score on your custom dataset.
54. Why Global Metrics Aren’t Enough

The slide discusses the limitations of the “Equivalence” approach. While good for a general sense of quality, Global Metrics miss nuances.
Sometimes it’s hard to get a Gold Answer for open-ended creative tasks. Furthermore, a simple “Pass/Fail” doesn’t tell you why the model failed (e.g., was it tone, length, or factuality?).
55. From Global to Targeted Evaluation

This slide argues for Targeted Evaluation. To maximize performance, you need to dig deeper into the data and identify specific error modes.
This transitions the talk from “Basic Workflow” to “Advanced Testing,” where we break down “Quality” into specific, testable components like tone, length, and safety.
56. Building Tests

The section title “Building Tests” appears. This is where the presentation moves into the “Unit Testing” philosophy for GenAI.
Just as software engineering relies on unit tests to verify specific functions, GenAI engineering should use targeted tests to verify specific attributes of the generated text.
57. Good vs. Bad Examples

The slide displays a Good Example and a Bad Example of a response. The bad example is visibly shorter and less polite.
Rajiv asks the audience to identify why it is bad. This exercise is crucial: you cannot build a test until you can articulate exactly what makes a response a failure.
58. Develop an Evaluation Mindset

To define “Bad,” developers need an Evaluation Mindset. This involves observing real-world user interactions and problems.
Data scientists often want to stay in their “chair” and optimize algorithms, but Rajiv argues that effective evaluation requires understanding the user’s pain points.
59. Collaborate with Experts

The slide stresses Collaboration. You must talk to domain experts (e.g., the customer support team) to define what a “good” answer looks like.
Naive bootstrapping—pretending to be a user—is a good start, but long-term success requires input from the people who actually know the business domain.
60. Identify and Categorize Failures
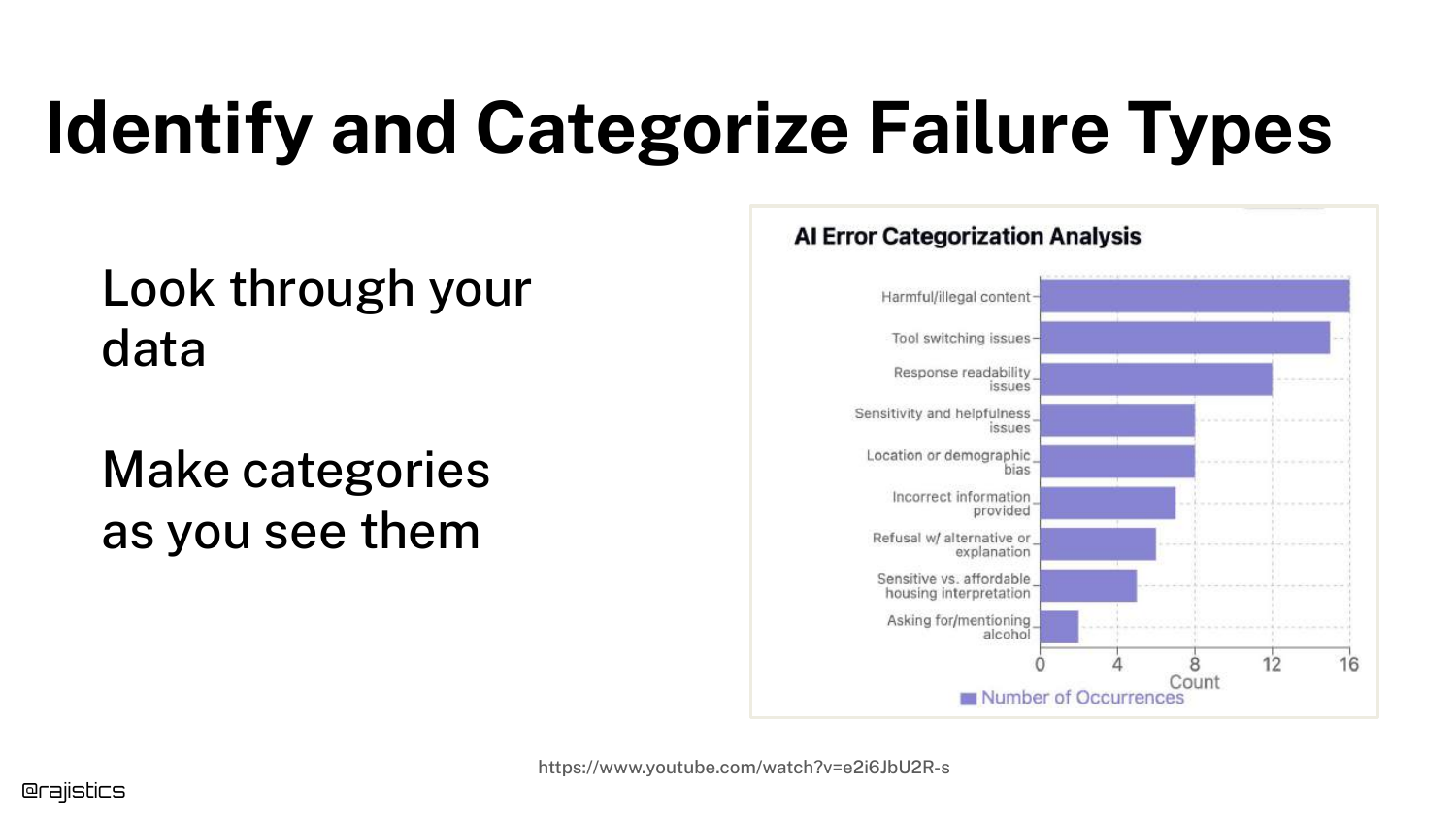
Once you understand the domain, you can Categorize Failure Types. The slide shows a chart grouping errors into categories like “Harmful Content,” “Bias,” or “Incorrect Info.”
This clustering allows you to see patterns. Instead of just knowing “the model failed 20% of the time,” you know “the model has a specific problem with tone.”
61. Define What Good Looks Like

Using the categorization, you can explicitly Define What Good Looks Like. The slide contrasts the good/bad examples again, but now with labels: “Too short,” “Lacks professional tone.”
This transforms a subjective feeling (“this response sucks”) into objective criteria (“response must be >50 words and use polite honorifics”).
62. Document Every Issue

The slide shows a spreadsheet where humans evaluate responses and Document Every Issue. Columns track specific attributes like “Is it helpful?” or “Is the tone right?”
This manual annotation is the training data for your automated tests. You need humans to establish the ground truth before you can automate the checking.
63. Evaluation Tooling
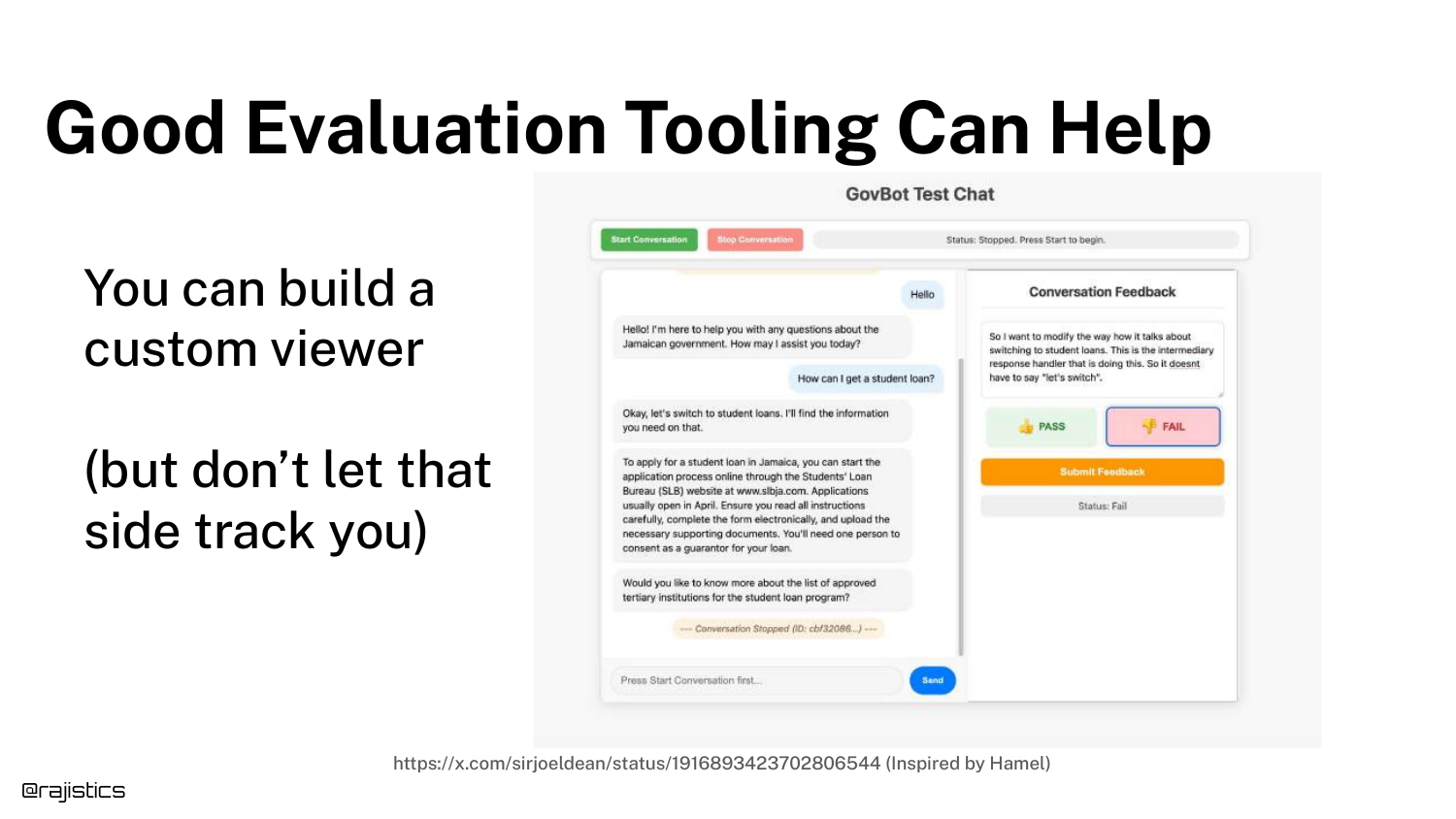
Rajiv mentions that Tooling Can Help. The slide shows a custom chat viewer designed to make human review easier.
However, he warns against getting sidetracked by building fancy tools. Simple spreadsheets often suffice for the early stages. The goal is the data, not the interface.
64. Test 1: Length Check

Now we build the automated tests. Test 1 is a Length Check. The slide shows Python code asserting that the word count is between 8 and 200.
This is a deterministic test. You don’t need an LLM to count words. Rajiv encourages using simple Python assertions wherever possible because they are fast, cheap, and reliable.
65. Test 2: Tone and Style

Test 2 checks Tone and Style. Since “tone” is subjective, we use an LLM Judge (OpenAI model) to classify the response.
The prompt asks the judge to identify the style. This allows us to automate the “vibe check” that humans were previously doing manually.
66. Adding Metrics to Documentation

The spreadsheet is updated with new columns: Length_OK and Tone_OK. These are the results of the automated tests.
Now, for every row in the dataset, we have granular pass/fail metrics. This helps pinpoint exactly why a specific response failed, rather than just a generic failure.
67. Check Judges Against Humans

A critical step: Check LLM Judges Against Humans. You must verify that your automated “Tone Judge” agrees with your human experts.
If the human says the tone is rude, but the LLM Judge says it’s polite, your metric is useless. You must iterate on the judge’s prompt until alignment is high.
68. Self-Evaluation Bias
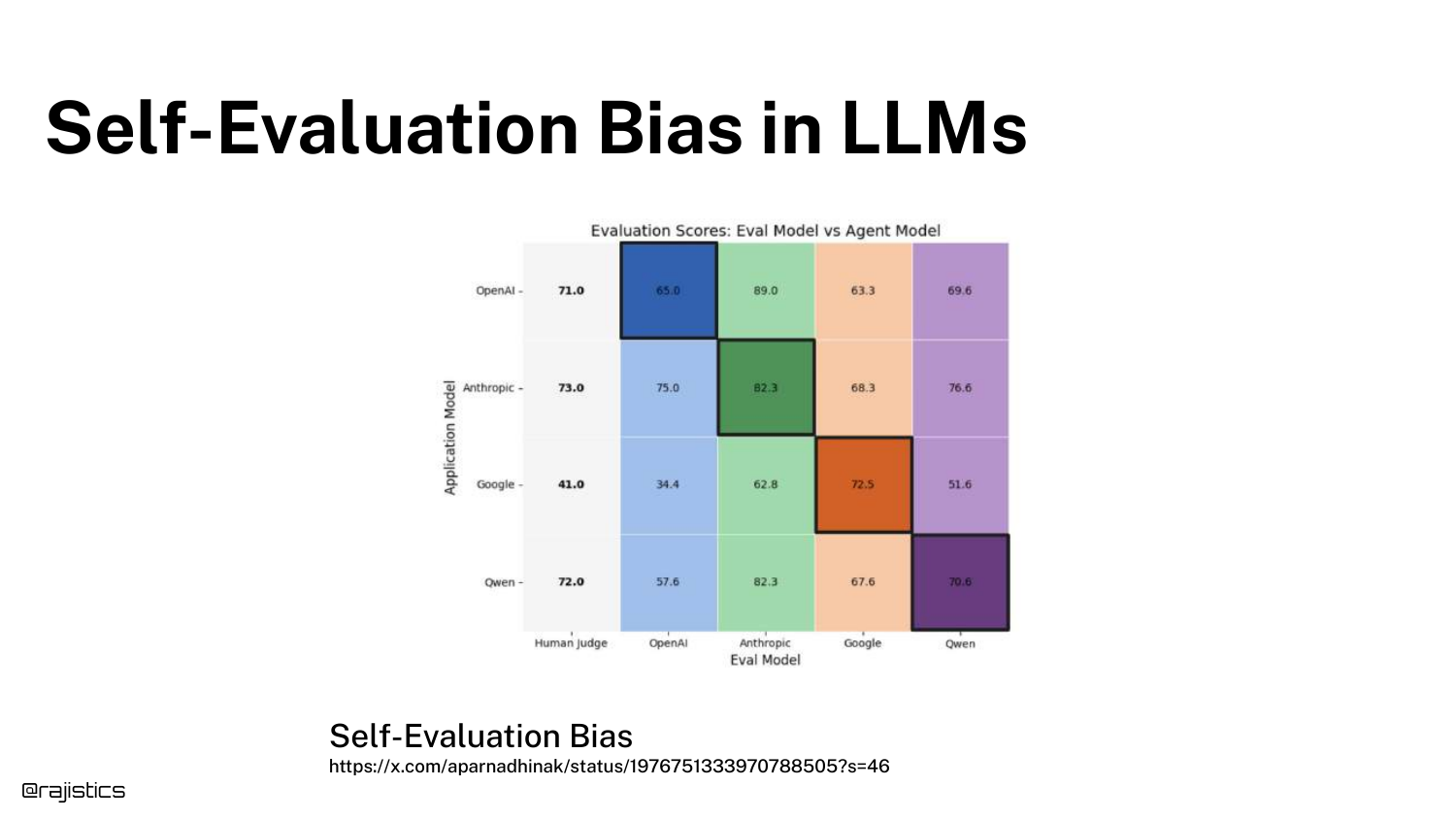
The slide illustrates Self-Evaluation Bias. LLMs tend to rate their own outputs higher than outputs from other models. GPT-4 prefers GPT-4 text.
To mitigate this, Rajiv suggests mixing models—use Claude to judge GPT-4, or Gemini to judge Claude. This helps ensure a more neutral evaluation.
69. Alignment Checks

This slide reinforces the need for Continuous Alignment. Just because your judge aligned with humans last month doesn’t mean it still does (due to model drift).
Human spot-checks should be a permanent part of the pipeline to ensure the automated judges haven’t drifted.
70. Biases in LLM Judges

The slide lists known Biases in LLM Judges, such as Position Bias (favoring the first answer presented) or Verbosity Bias (favoring longer answers).
Evaluators must be aware of these. For example, you should shuffle the order of answers when asking a judge to compare two options to cancel out position bias.
71. Best Practices for LLM Judges

A summary of Best Practices: Calibrate with human data, use ensembles (multiple judges), avoid asking for “relevance” (too vague), and use discrete rating scales (1-5) rather than continuous numbers.
These tips help stabilize the inherently noisy process of using AI to evaluate AI.
72. Error Analysis Chart
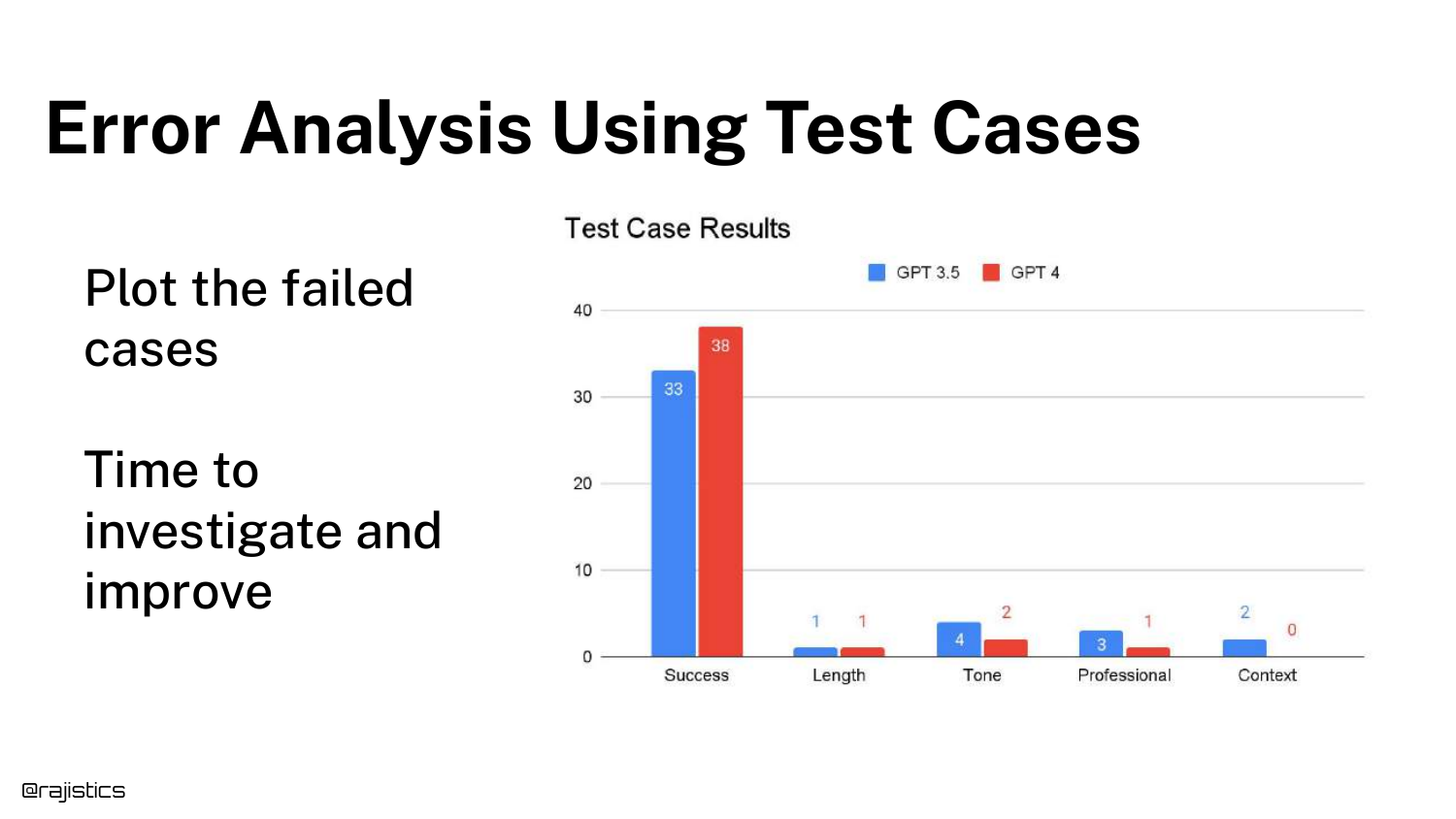
With tests in place, we move to Error Analysis. The bar chart shows the number of failed cases categorized by error type (Length, Tone, Professional, Context).
This visualization tells you where to focus your efforts. If “Tone” is the biggest bar, you work on the system prompt’s tone instructions. If “Context” is the issue, you might need better Retrieval Augmented Generation (RAG).
73. Comparing Prompts
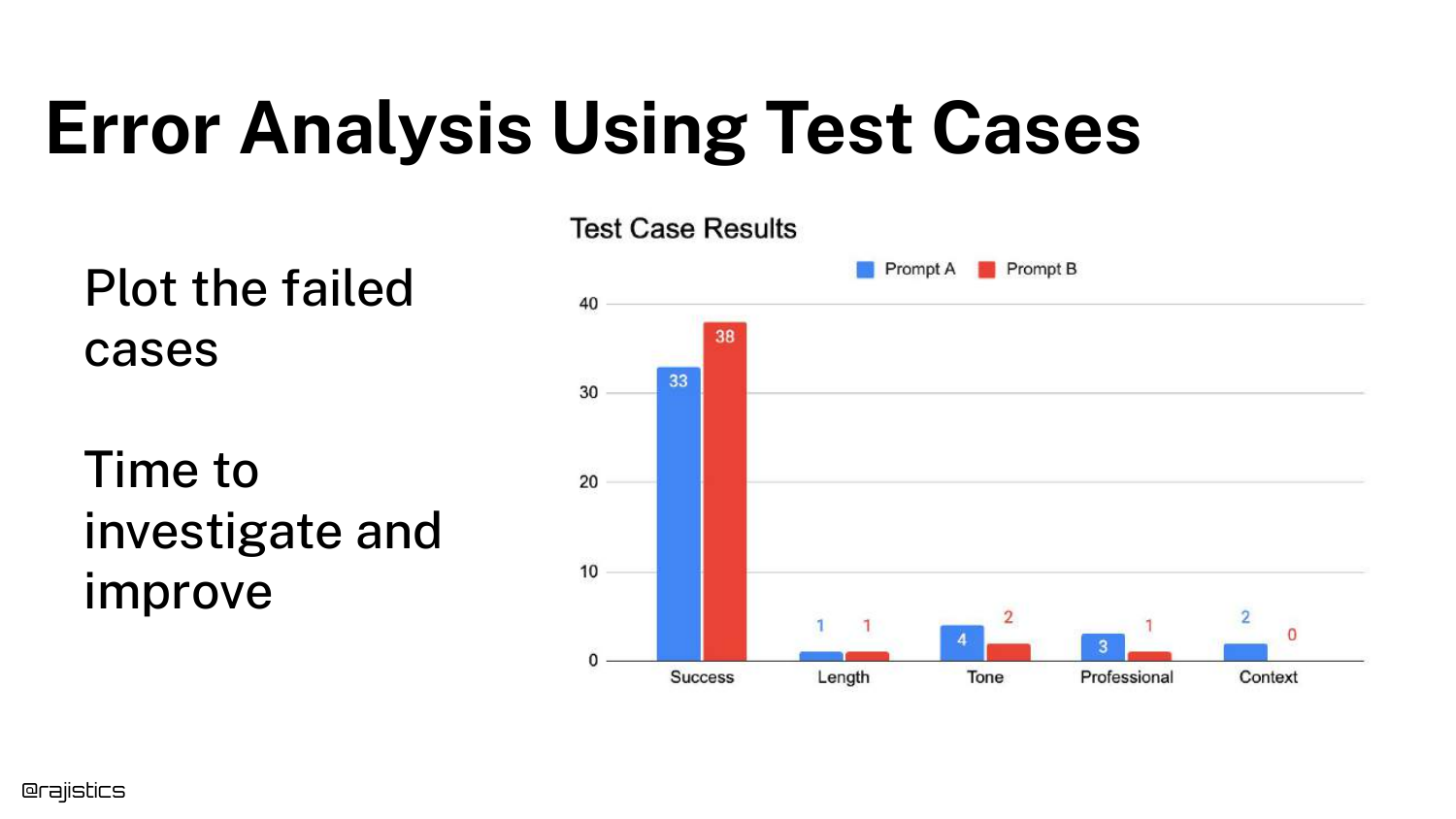
The chart can compare Prompt A vs. Prompt B. This allows for A/B testing of prompt engineering strategies.
You can see if a new prompt improves “Tone” but accidentally degrades “Context.” This tradeoff analysis is impossible with a single global score.
74. Explanations Guide Improvement

Rajiv suggests asking the LLM Judge for Explanations. Don’t just ask for a score; ask for “one sentence explaining why.”
These explanations act as metadata that helps developers understand the judge’s reasoning, making it easier to debug discrepancies between human and AI judgments.
75. Limits to Explanations

A warning: Explanations are not causal. When an LLM explains why it did something, it is generating a plausible justification, not a trace of its actual neural activations.
Treat explanations as a heuristic or a helpful hint, not as absolute truth about the model’s internal state.
76. The Evaluation Flywheel
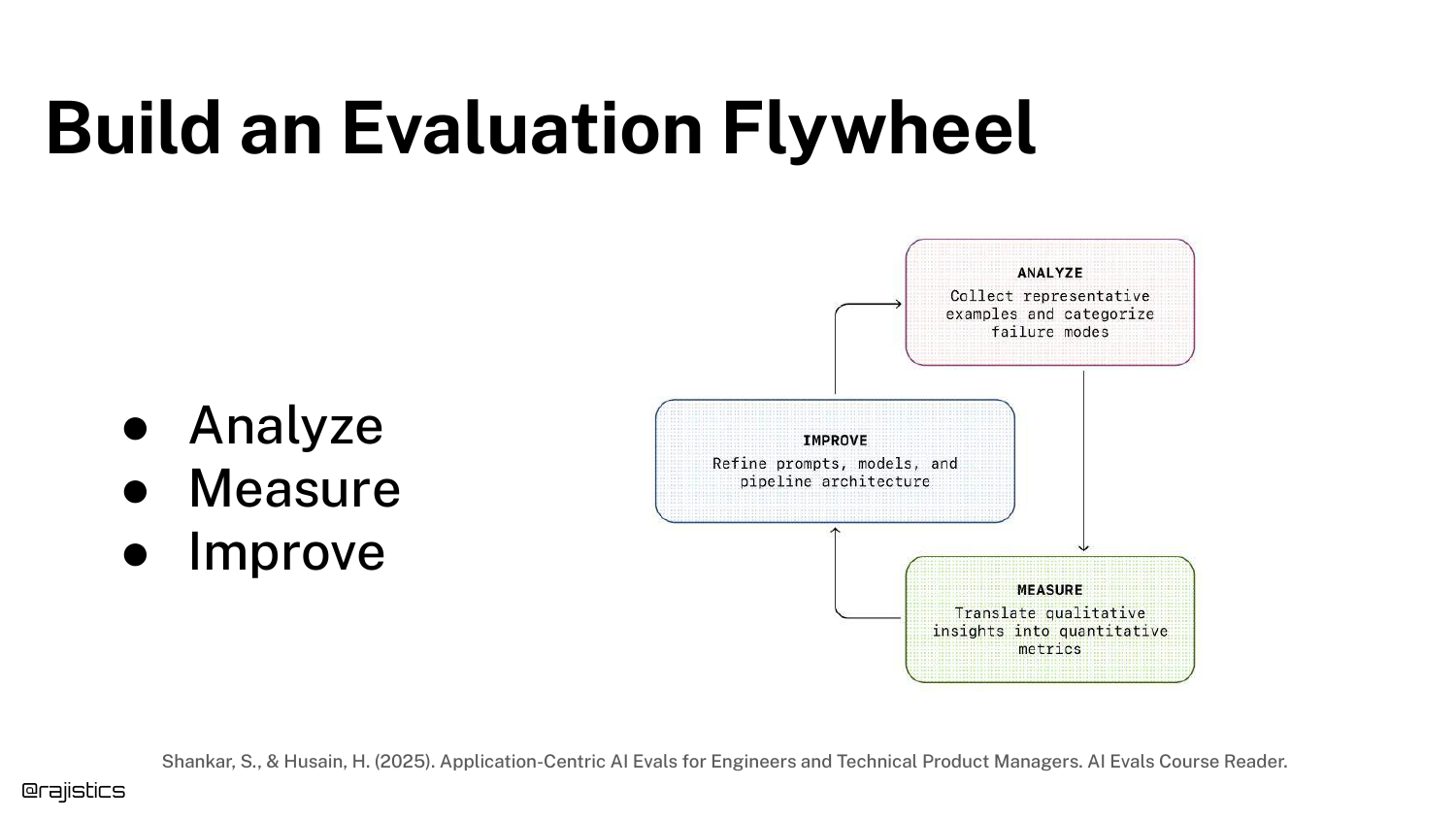
The Evaluation Flywheel describes the iterative cycle: Build Eval -> Analyze -> Improve -> Repeat.
This concept, credited to Hamill, emphasizes that evaluation is not a one-time event but a continuous loop that spins faster as you gather more data and build better tests.
77. Financial Analyst Agent Example

To demonstrate advanced unit testing, Rajiv introduces a Financial Analyst Agent. The goal is to assess the specific “style” of a financial report.
This is a complex domain where “good” is highly specific (regulated, precise, risk-aware), making it a perfect candidate for granular unit tests.
78. Use a Global Test?

You could use a Global Test: “Was this explained as a financial analyst would?”
While simple, this test is opaque. If it fails, you don’t know if it was because of compliance issues, lack of clarity, or poor formatting.
79. Global vs. Unit Tests

The slide contrasts the Global approach with Unit Tests. Instead of one question, we ask six: Context, Clarity, Precision, Compliance, Actionability, and Risks.
This breakdown allows for targeted debugging. You might find the model is great at “Clarity” but terrible at “Compliance.”
80. Scoring Radar Chart

A Radar Chart visualizes the unit test scores. This allows for a quick visual assessment of the model’s profile.
It facilitates comparison: you can overlay the profiles of two different models to see which one has the better balance of attributes for your specific needs.
81. Analyzing Failures with Clusters

With enough unit test data, you can use Clustering (e.g., K-Means) to group failures. The slide shows clusters like “Synthesis,” “Context,” and “Hallucination.”
This moves error analysis from reading individual logs to analyzing aggregate trends, helping you prioritize which class of errors to fix first.
82. Designing Good Unit Tests

Advice on Designing Unit Tests: Keep them focused (one concept per test), use unambiguous language, and use small rating ranges.
Good unit tests are the building blocks of a reliable evaluation pipeline. If the tests themselves are noisy or vague, the entire system collapses.
83. Examples of Unit Tests

The slide lists specific examples of tests for Legal (Compliance, Terminology), Retrieval (Relevance, Completeness), and Bias/Fairness.
This serves as a menu of options for the audience, showing that unit tests can cover almost any dimension of quality required by the business.
84. Evaluating New Prompts
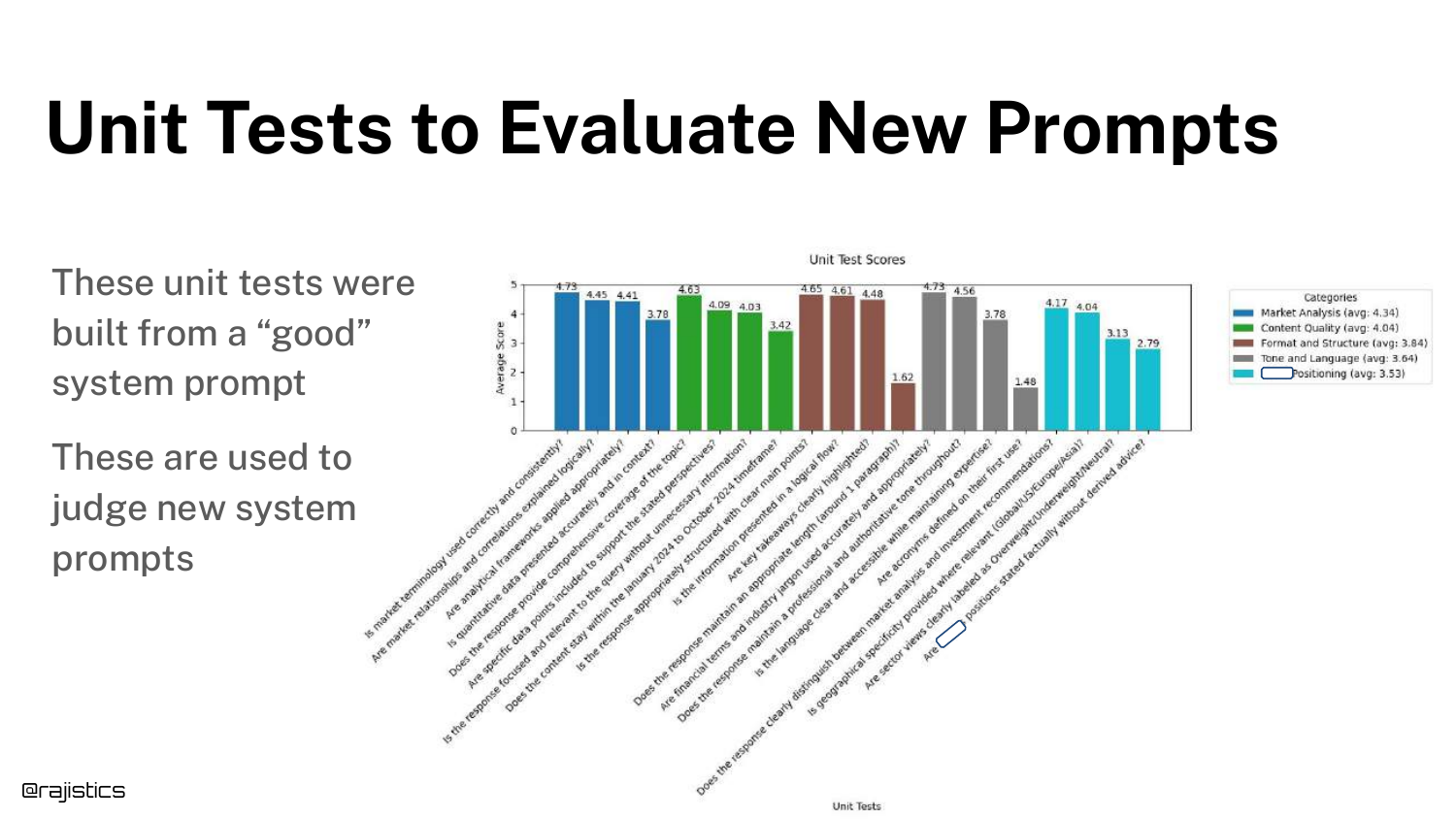
A bar chart shows how unit tests are used to Evaluate New Prompts. By running the full suite of unit tests on a new prompt, you get a “scorecard” of its performance.
This data-driven approach removes the guesswork from prompt engineering.
85. Tools - No Silver Bullet

Rajiv reminds the audience that Tools are No Silver Bullet. You must master the basics (datasets, metrics) first.
He advises logging traces and experiments and practicing Dataset Versioning. Tools facilitate these practices, but they cannot replace the fundamental engineering discipline.
86. Forest and Trees

An analogy helps structure the analysis: Forest (Global/Integration) vs. Trees (Test Case/Unit Tests).
You need to look at both. The forest tells you the overall health of the app, while the trees tell you specifically what needs pruning or fixing.
87. Change One Thing at a Time

A crucial scientific principle: Change One Thing at a Time. With so many knobs (prompt, temp, model, RAG settings), changing multiple variables simultaneously makes it impossible to know what caused the improvement (or regression).
Isolate your variables to conduct valid experiments.
88. Error Analysis Tips

A summary of Error Analysis Tips: Use ablation studies (removing parts to see impact), categorize failures, save interesting examples, and leverage logs/traces.
These are the daily habits of successful GenAI engineers.
89. The Evaluation Story
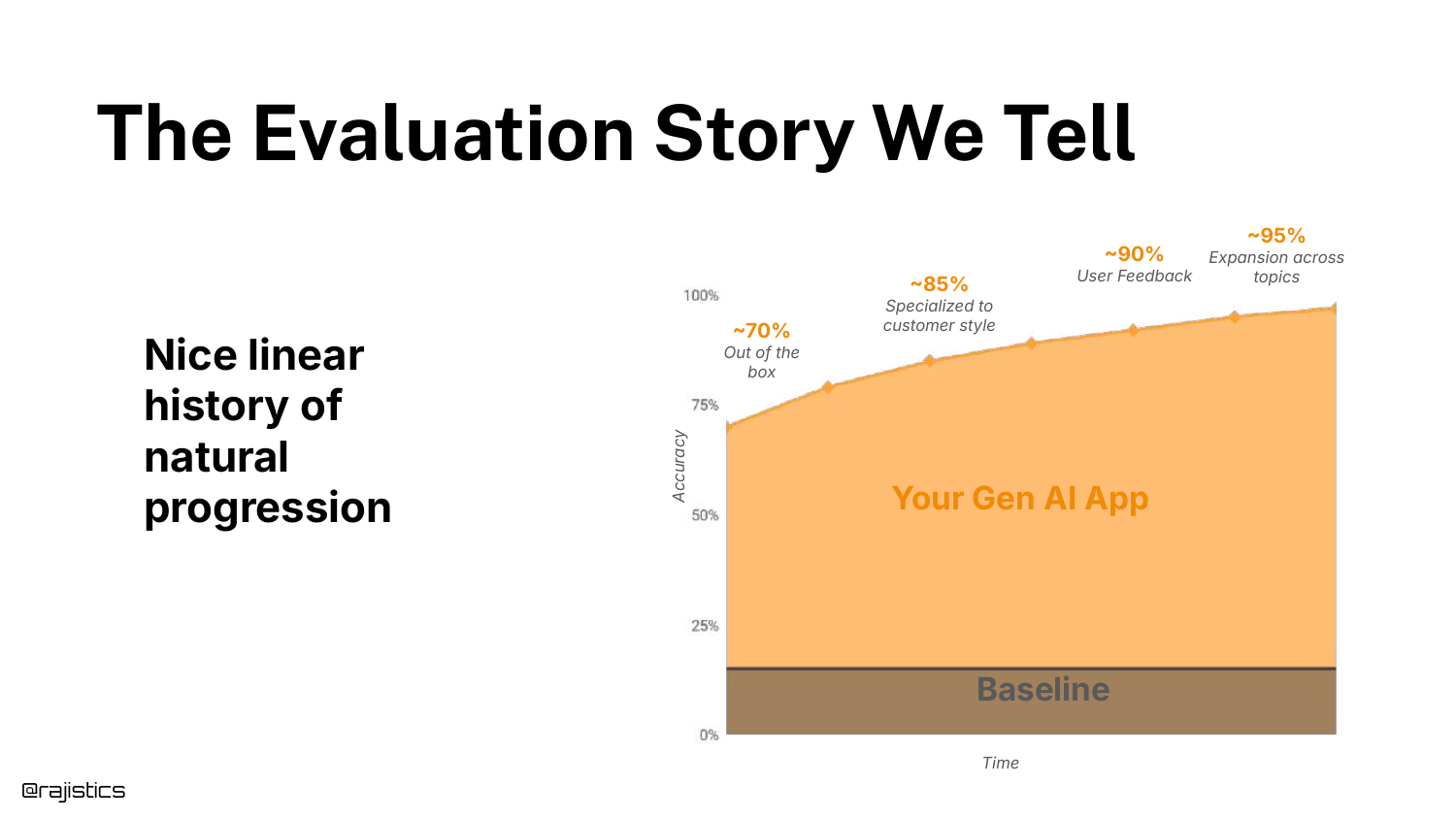
The slide shows the “Story We Tell”—a linear graph of improvement over time. This is the idealized version of progress often presented in case studies.
It suggests a smooth journey from “Out of the box” to “Specialized” to “User Feedback.”
90. The Reality of Progress

The Reality is a messy, non-linear graph. You take two steps forward, one step back. Sometimes an “improvement” breaks the model.
Rajiv encourages resilience. Experienced practitioners know that this messy graph is normal and that sticking to the process eventually yields results.
91. Continual Process
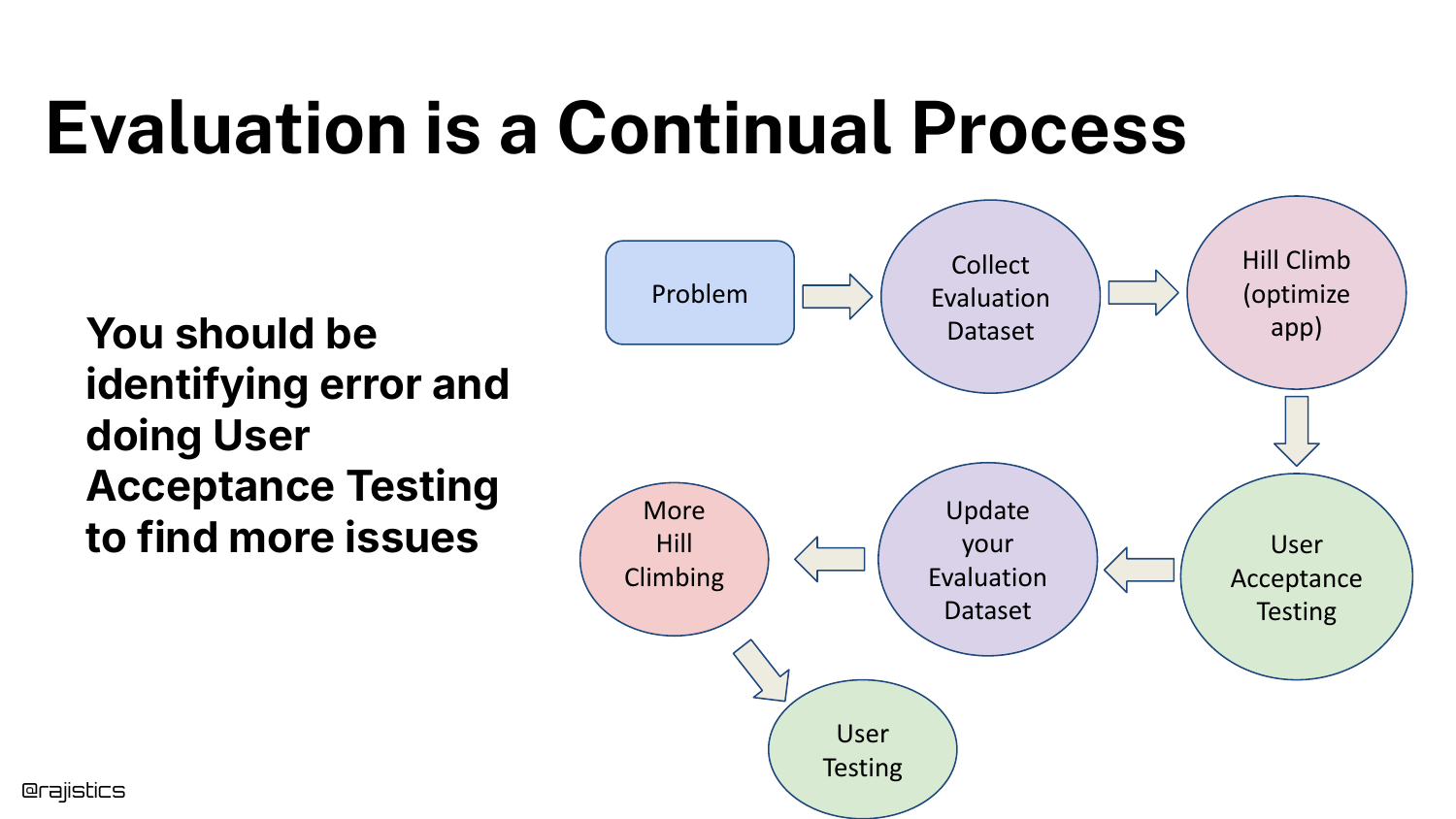
Evaluation is a Continual Process. It involves Problem ID, Data Collection, Optimization, User Acceptance Testing (UAT), and Updates.
Crucially, UAT is your holdout set. Since you don’t have a traditional test set in GenAI, your real users act as the final validation layer.
92. Eating the Elephant

The metaphor “How do you eat an elephant?” addresses the overwhelming nature of building a comprehensive evaluation suite.
The answer, of course, is “one bite at a time.” You don’t need 100 tests on day one.
93. Adding Tests Over Time

The slide visualizes the “elephant” being broken down into bites. You start with a few critical tests. As the app matures and you discover new failure modes, you add more tests.
Six months in, you might have 100 tests, but you built them incrementally. This makes the task manageable.
94. Doing Evaluation the Right Way

A summary slide listing best practices: Annotated Examples, Systematic Documentation, Continuous Error Analysis, Collaboration, and awareness of Generalization.
This concludes the core methodology section of the talk.
95. Agentic Use Cases

The final section covers Agentic Use Cases, symbolized by a dragon. Agents add a layer of complexity because the model is now making decisions (routing, tool use) rather than just generating text.
This “agency” makes the system harder to track and evaluate.
96. Crossing the River

A conceptual slide asking, “How should it cross the river?” (Fly, Swim, Bridge?). This represents the decision-making step in an agent.
Evaluating an agent requires evaluating how it made the decision (the router) separately from how well it executed the action.
97. Chat-to-Purchase Router
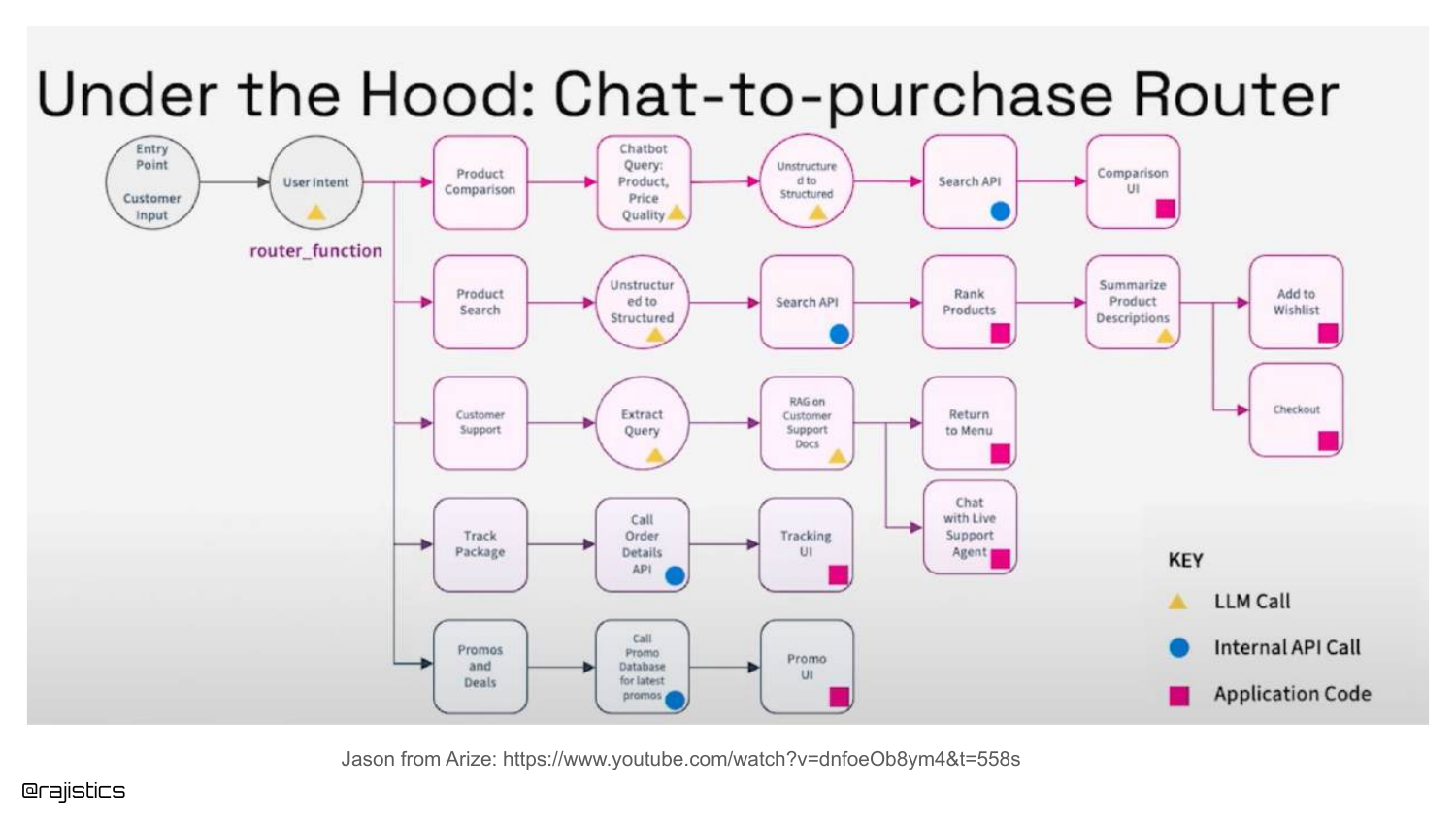
A complex flowchart shows a Chat-to-Purchase Router. The agent must decide if the user wants to search for a product, get support, or track a package.
Rajiv suggests breaking this down: evaluate the Router component first (did it pick the right path?), then evaluate the specific workflow (did it track the package correctly?).
98. Text to SQL Agent
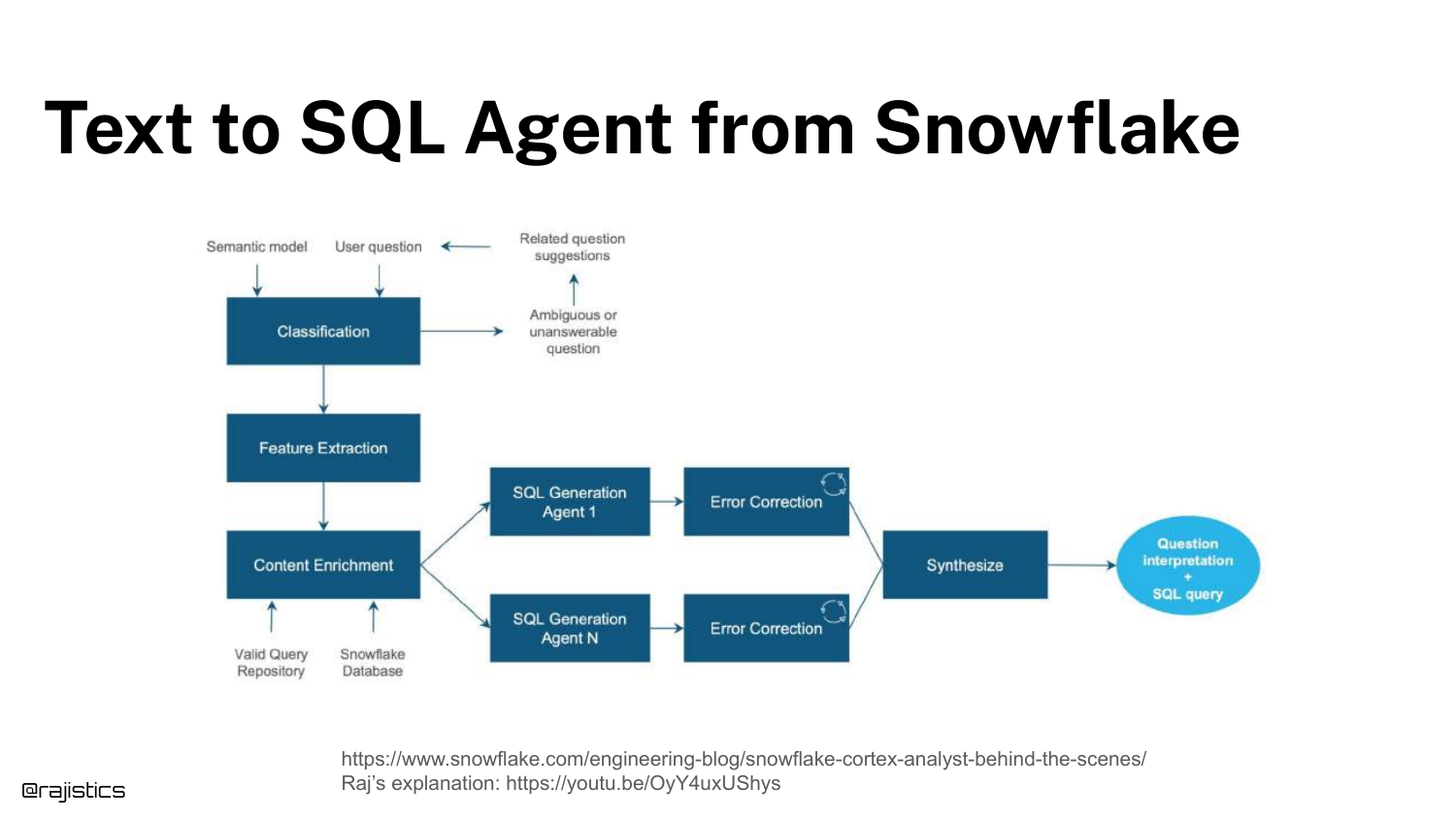
Another example: Text to SQL Agent. This workflow involves classification, feature extraction, and SQL generation.
You can isolate the “Classification” step (is this a valid SQL question?) and build a test just for that, before testing the actual SQL generation.
99. Evaluating Office-Style Agents

The slide discusses OdysseyBench, a benchmark for office tasks. It highlights failure modes like “Failed to create folder” or “Failed to use tool.”
Evaluating agents involves checking if they successfully manipulated the environment (files, APIs), which is a functional test rather than a text similarity test.
100. Error Analysis for Agents
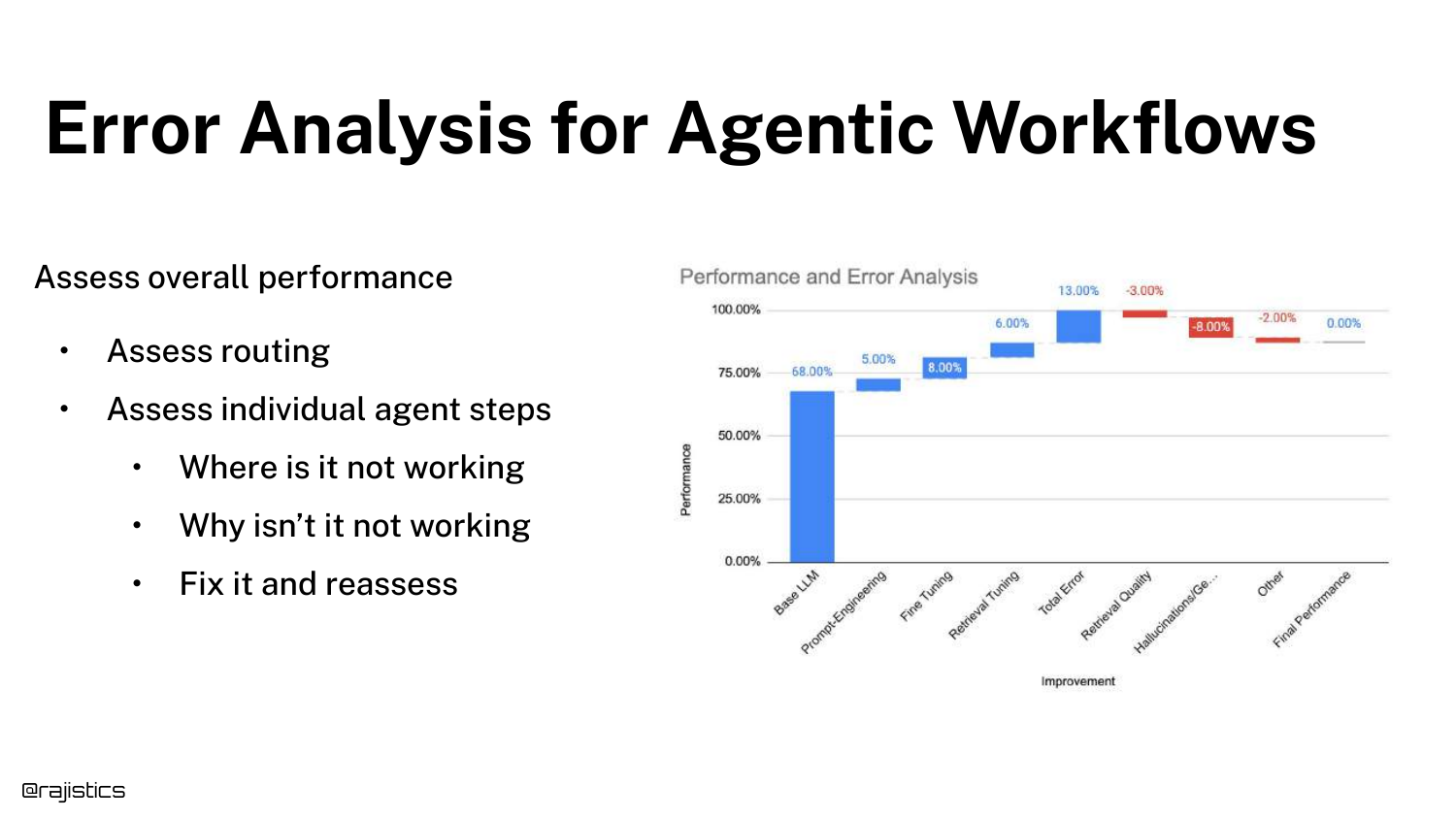
Error Analysis for Agentic Workflows requires assessing the overall performance, the routing decisions, and the individual steps.
It is the same “action error analysis” process but applied recursively to every node in the agent’s decision tree.
101. Evaluating Workflow vs. Response
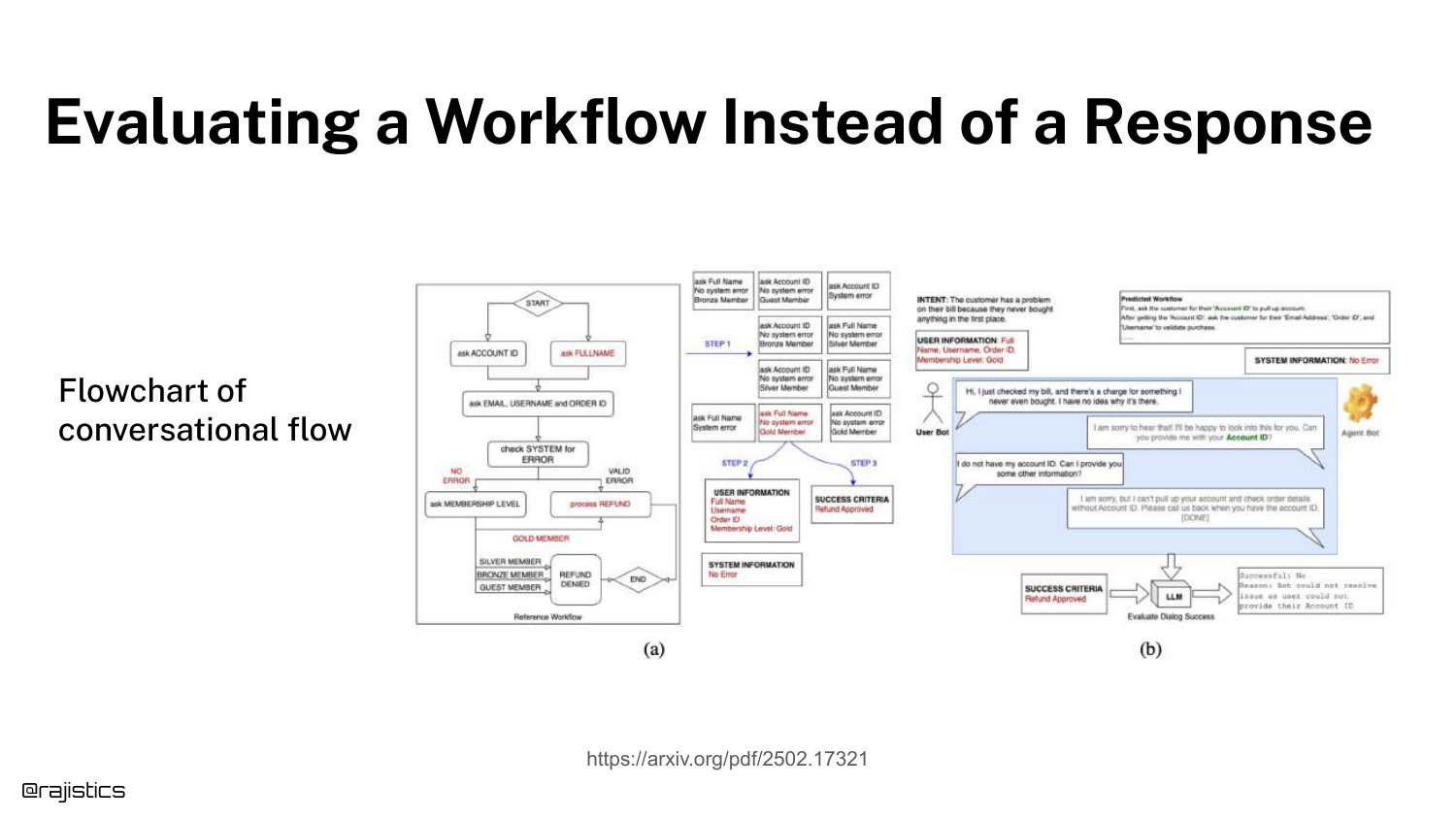
This slide distinguishes between evaluating a Response (text) and a Workflow (process). The flowchart shows a conversational flow.
Evaluating a workflow might mean checking if the agent successfully moved the user from “Greeting” to “Resolution,” regardless of the exact words used.
102. Agentic Frameworks

Rajiv warns that “Agentic Frameworks Help – Until They Don’t.” Frameworks (like LangChain or AutoGen) are great for demos because they abstract complexity.
However, in production, these abstractions can break or become outdated. He often recommends using straight Python for production agents to maintain control and reliability.
103. Abstraction for Workflows
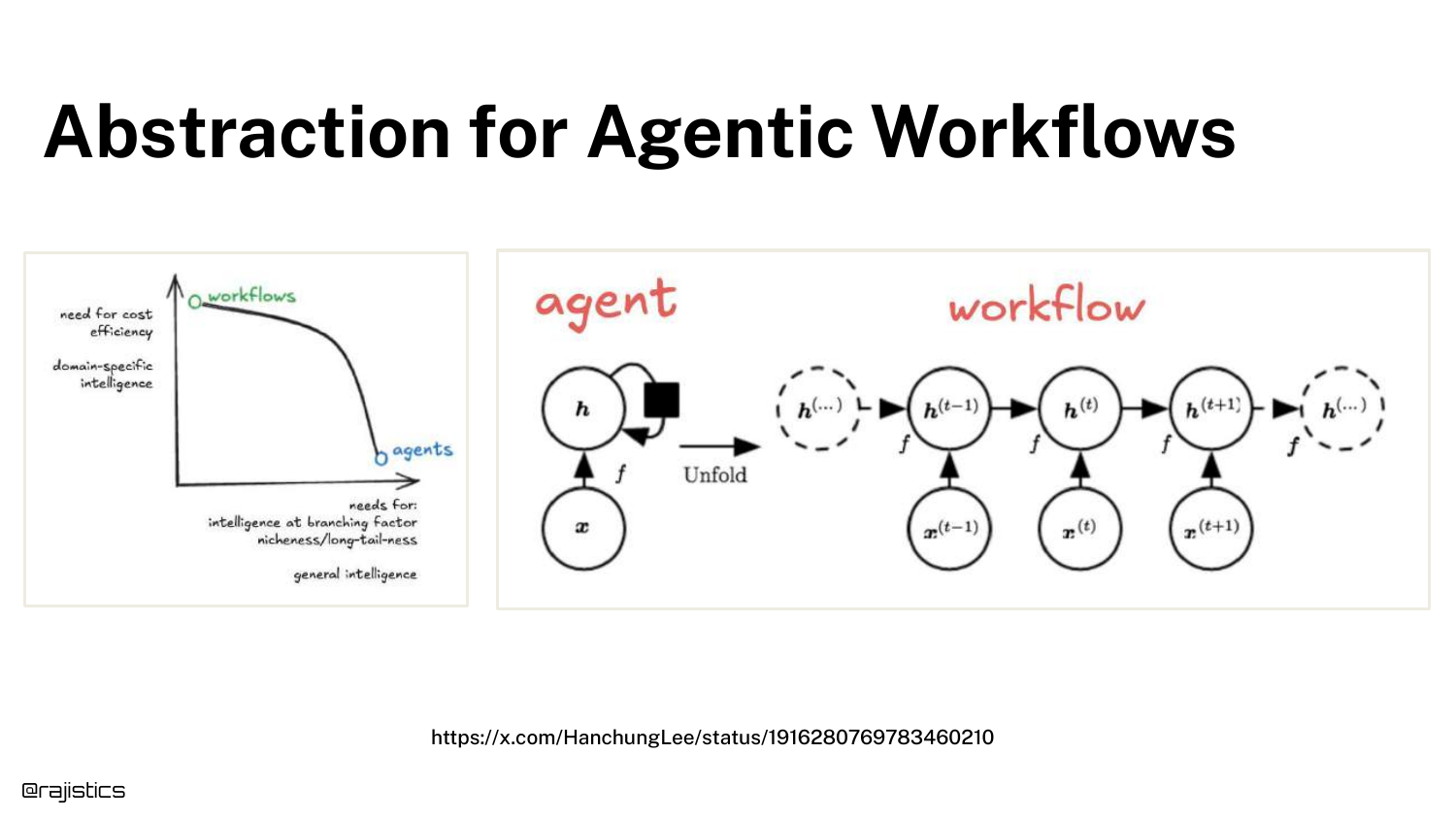
The slide illustrates the trade-off in Abstraction. You can build rigid workflows (orchestration) where you control every step, or use general agents where the LLM decides.
Orchestration is more reliable but rigid. General agents are flexible but prone to non-deterministic errors.
104. When Abstractions Break

Model providers are training models to handle workflows internally (removing the need for external orchestration).
However, until models are perfect, developers often need to break tasks down into specific pieces to ensure reliability. The choice between “letting the model do it” and “scripting the flow” depends on the application’s risk tolerance.
105. Lessons from Agent Benchmarks

The slide lists Lessons from Reproducing Agent Benchmarks: Standardize evaluation, measure efficiency, detect shortcuts, and log real behavior.
These are advanced tips for those pushing the boundaries of what agents can do.
106. Conclusion

The final slide, “We did it!”, concludes the presentation. Rajiv thanks the audience and provides the QR code again.
His final message is one of empowerment: he hopes the audience now has the confidence to go out, build their own evaluation datasets, and start “hill climbing” their own applications.
This annotated presentation was generated from the talk using AI-assisted tools. Each slide includes timestamps and detailed explanations.